Subsections
Slides brukt i forelesningen
Uredigert opptak av hele første time av forelesningen ( 00:38:06)
Uredigert opptak av hele andre time av forelesningen ( 01:09:50)
En harddisk består av et antall plater av et magnetisk materiale. For hver plate er
det et lese/skrive-hode som kan lese/skrive bits ved å måle magnetisering/magnetisere
platene. De fleste disker lagrer data på begge sider av platene og har derfor lese/skrive-hode
over og under.
Denne linken
viser en video av en åpen harddisk mens den kjører.
Det området som lesehodet dekker under en rotasjon, kalles en track og en track er
delt opp i sektorer. En sektor er
- grunnenhet for disker
- vanligvis på 512 bytes
- minste enhet som kan leses/skrives til.
Noen ganger brukes begrepet sektor om alle tracks i en retning på disken.
En sylinder er samlingen av alle tracks fra alle platene i disken som ligger i
samme avstand fra sentrum.
Adressen til den minste lesbare enheteten, en sektor, er derfor gitt ved tre parametre [leshode, track, sektornummer].
Når OS vil lese noe fra disk, sendes en forespørsel med disse tre tallene.
En disk-partisjon defineres som et antall sylindere som ligger fysisk samlet etter hverandre. For eksempel kan man bestemme at
alle sylindere fra og med nummer 150 til og med 672 skal utgjøre en partisjon. Dette er den største enheten man deler inn
en disk i. Under Windows er det vanlig ha en stor partisjon som utgjør hele disken, mens det under Linux er vanlig å dele
inn disken i flere partisjoner. Monteringspunkter i filsystemet kan da tildeles bestemte partisjoner slik at for eksempel
alt som ligger under /home legges på partisjon nummer 3 på disken.
Noen av fordelene med partisjoner er:
- Hvis man har en egen partisjon for brukeres filer og partisjonen som OS ligger på blir ødelagt eller
OS av andre grunner må installeres på nytt, vil man kunne beholde partisjonen med brukerfiler.
- Hvis man bare har en disk, kan man likevel ha forskjellige filsystemer og dermed forskjellige OS på
den samme disken når den er delt i partisjoner.
- Mindre partisjoner og dermed mindre filsystemer er noe hurtigere enn å ha alt på en partisjon.
- Filsystemene på partisjoner kan tilpasses dataene som skal ligge der. For eksempel stor
cluster-størrelse til videofilmer.
- Basert på flash-minne som i minnepinner og har ingen bevegelige deler
- Tåler rystelser bedre og er lydløs
- Rask random aksesstid, 0.1 ms mot 5-10 ms for roterende disker
- Dyrere enn tradisjonelle disker og mindre kapasitet
Før en ny disk kan tas i bruk må den formatteres. Dette er en lavnivå organisering av disken som vanligvis gjøres på
fabrikken der den deles inn i sektorer, som for de fleste harddisker er på 512 byte.
Når dette er gjort kan disk-controlleren lese og skrive til disse sektorene. Når man senere bruker software til å
formattere en disk, er dette en høynivå formattering som setter disken tilbake til slik den var når den var ny, og i tillegg
gjør operasjoner som å legge inn en boot-sektor. Før operativsystemet og applikasjoner kan ta
disken i bruk må det så lages et filsystem på disken. Det finnes mange forskjellige filsystemer, NTFS er det vanligste på
Windows, tidligere var FAT det vanligste. På Linux er filsystemet ext3 det vanligste.
Hvis disken er inndelt i flere partisjoner, kan det lages forskjellige filsystemer på de forskjellige partisjonene.
Fra Windows kan man ikke uten videre lese og skrive til partisjoner med ext3,
men fra Linux kan man lese og skrive til parisjoner med FAT og NTFS.
Filsystemet tar utganspunkt i den miste enheten som kan leses fra eller skrives til, sektoren som typisk er på 512 bytes.
Den viktigste oppgaven til filsystemet er å fordele mapper og filer på diskens sektorer og holde orden på
hvor alt ligger. I de fleste tilfeller er en sektor for liten til å være en optimal størrelse for inndelingen av en disk og
filsystemet deler derfor disken inn i større blokker (Linux: blocks, Windows: clustere). Størrelsen på blokkene må bestemmes
når filsystemet lages og fordeler og ulemper ved store/små blokker må da veies mot hverandre.
- Store blokker
- Lese og skrive går hurtig, større sammenhengende områder
- En liten fil vil bruke unødvendig mye plass
- Bra til store filer, bilder og video
- Små blokker
- Små filer bruker mindre diskplass
- Større filer kan risikere å bli spredt rundt på disken
- Lese og skrive store filer går da saktere
- Bra hvis filsystemet skal inneholde mange små filer
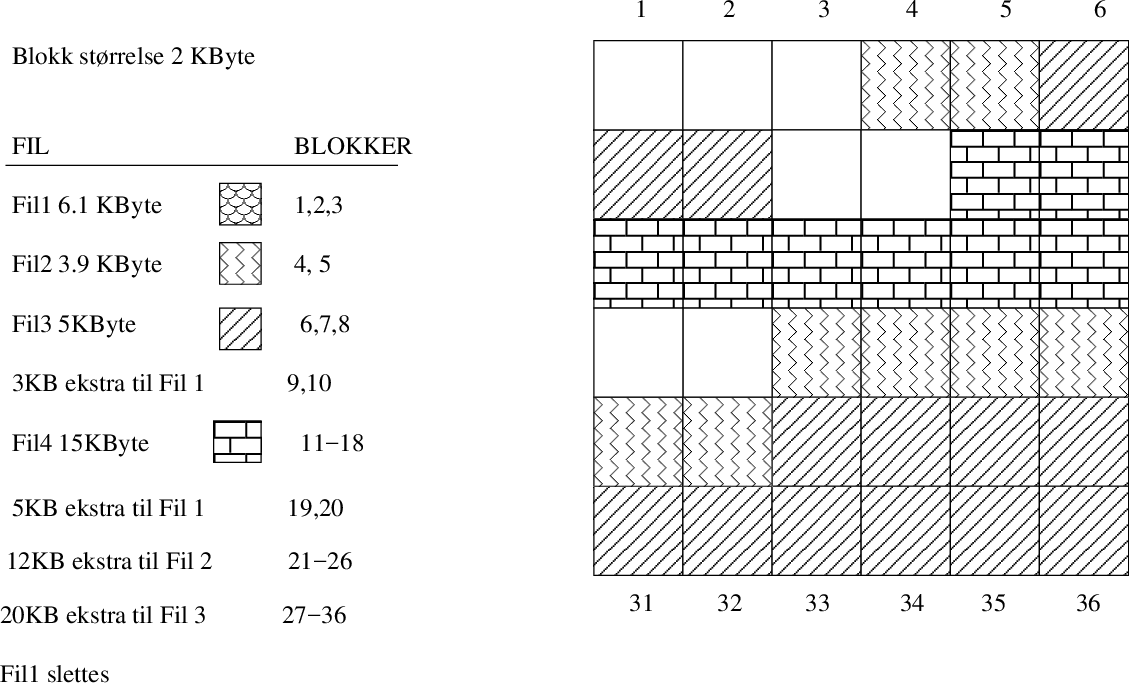
Alle filsystemer har en oversikt over hvilke blokker enhver fil på systemet består av. Når en fil lages,
vil den om mulig lagres på sammenhengende blokker. Når filene øker vil den dynamisk tildeles flere blokker,
men da kan det være at det ikke er plass ved siden av de opprinnelige blokkene og filen må spres på flere
områder av disken.
En oppdeling av filer rundt om kring på disken som resultat av dynamisk allokering når filer vokser,
kalles fragmentering og den blir ofte ganske omfattende på
disker som er mye i bruk og hvor det meste av plassen blir brukt. Under Windows kan man defragmentere
disken med Disk Defragmenter. Det må da være minst 15% ledig plass og prosessen kan ta lang tid. For Linux
ext-filsystemer finnes det ikke noen innebygd defragmenterer, men det finnes slike verktøy som kan installeres.
Når en fil slettes, vil de fleste filsystemer bare slette informasjonen om filene og hvilke blokker som tilhører
filene og ikke slette innholdet av blokkene. Dermed kan man med applikasjoner som autopsy eller ved å se på et
disk-image direkte med en hex-editor finne igjen hele eller deler av en slettet fil.
Det finnes egne applikasjoner som brukes til å slette filer bedre ved å skrive over innholdet av filene med nuller eller
tilfeldige bit. Selvom man gjør en slik operasjon flere ganger, kan man med måleinstrumenter som er enda mer
nøyaktige enn standard lese/skrive-hoder finne ut hva som opprinnelig var skrevet. Et eksempel på dette kan sees i
Fig. 86.
Bildet er hentet fra boken Forensic Discovery av Farmer og Venema som er tilgjengelig online.
Først må man lage en tom fil av den størrelse man ønsker på image't.
haugerud@lap:~/disk/mount$ dd if=/dev/zero of=minfil bs=8M count=1
1+0 records in
1+0 records out
8388608 bytes (8,4 MB, 8,0 MiB) copied, 0,00784602 s, 1,1 GB/s
|
Dette lager en 8 MiB fil med null-tegn (ASCII tegn nummer null). Deretter kan man bygge et filsystem på denne filen:
haugerud@lap:~/disk/mount$ mkfs -t ext3 minfil
mke2fs 1.44.1 (24-Mar-2018)
Discarding device blocks: done
Creating filesystem with 8192 1k blocks and 2048 inodes
Allocating group tables: done
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done
|
Deretter kan dette image't monteres i filsystemet på helt samme måte som om det var en disk:
haugerud@lap:~/disk/mount$ sudo mount minfil /mnt
[sudo] password for haugerud:
haugerud@lap:~/disk/mount$ cd /mnt/
haugerud@lap:/mnt$ ls -l
total 12
drwx------ 2 root root 12288 april 27 00:10 lost+found
|
Tidligere måtte man eksplisitt bruke opsjonen -o loop for å montere en fil, men det fungerer nå uten å spesifisere det.
Windows NT File System er filsystemet til Windows NT/XP/7/8/10/11 og er standard filsystem for alle
moderne Windows-installasjoner. I tillegg til NTFS støttes også FAT16 og FAT32, blant annet for
kompatibilitet med USB-minnepinner og andre flyttbare medier.
- Disken deles inn i clustere, som er den minste enheten filsystemet opererer med
- Clusterstørrelse kan være 512 bytes, 1 KiB, 2 KiB, 4 KiB og opp til maks 64 KiB
- 4 KiB clustere er default for disker på 2 GiB eller mer
- Clusterne adresseres med 64 bits pekere, noe som gir mulighet for svært store volum
- Støtter komprimering av filer og mapper, men kun med clusterstørrelse på 4 KiB eller mindre
- Kryptering av filer og mapper med EFS (Encrypting File System)
- Alle endringer i filsystemets metadata logges i en journal ($LogFile), men selve dataendringer logges ikke
- Journalen gjør det raskt å gjenopprette filsystemet ved strømbrudd eller disk-crash, fordi man bare
trenger å spille av eller rulle tilbake de siste transaksjonene i stedet for å sjekke hele disken
Et volum er en logisk enhet som filsystemet defineres for. Det trenger ikke tilsvare en fysisk disk.
- Et volum består av en eller flere clustere
- Kan omfatte deler (partisjoner) av en disk, en hel disk, eller flere disker
- Dynamiske volum kan spenne over flere fysiske disker, for eksempel som spanned volumes eller striped volumes (RAID 0)
- Filsystemet defineres for dette volumet
- Maksimum antall clustere i et volum er
- Med 4 KiB clustere gir dette en maksimal volumstørrelse på
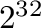
- Større clustere gir mulighet for enda større volum, men kan da ikke bruke komprimering
Den viktigste datastrukturen i et NTFS-volum er Master File Table (MFT). MFT inneholder informasjon
om hver eneste fil og mappe på volumet, inkludert seg selv.
- MFT-filen starter med 16 records som inneholder metadata om selve filsystemet, deretter følger
en record for hver fil og mappe på volumet
- Hver record er på 1 KB og inneholder all informasjon om filen, organisert som attributter
- Eksempler på attributter: tidsstempler, filnavn, sikkerhetsinfo og selve dataene eller pekere til clusterne der dataene ligger
- Små filer (under ca. 700 bytes) kan lagres direkte i MFT-recorden. Dette kalles resident data
og gjør at små filer kan leses med bare ett disk-oppslag
- For større filer inneholder MFT-recorden pekere (run lists) til de clusterne på disken der dataene
faktisk ligger. Dette kalles non-resident data
- Hvis det ikke er plass til alle pekerne i én record, lages det en attributtliste som peker til
en eller flere ekstra MFT-records
- Rettigheter og sikkerhetsinformasjon ble tidligere lagret direkte i hver fil-record. Fra NTFS 3.0
(Windows 2000) lagres dette sentralt i metadatafilen $Secure, noe som sparer plass siden
mange filer ofte har identiske rettigheter
- Windows reserverer en del av diskplassen til MFT for å redusere fragmentering av selve MFT-filen.
Dersom MFT likevel fragmenteres, kan dette redusere ytelsen merkbart
- OS-kjernen behandler hver fil som et objekt med tilhørende attributter
De 16 første MFT-recordene har spesielle roller og er vist i Fig. 87.
Attributtene som kan finnes i en MFT-record er vist i Fig. 88. Data-attributtet inneholder enten
selve filens data (for små filer) eller pekere til clusterne der dataene ligger.
Eksempelet under er informasjon som gis når man
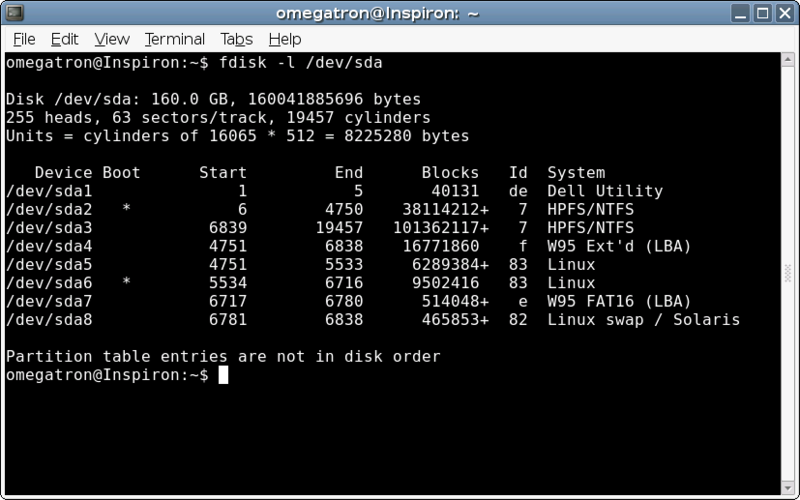
velger p for print fra menyen etter at man som root har kjørt kommandoen fdisk /dev/hda på en linux PC:
Disk /dev/hda: 61.4 GB, 61492838400 bytes
255 heads, 63 sectors/track, 7476 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 608 4883728+ 83 Linux
/dev/hda2 609 624 128520 82 Linux swap / Solaris
/dev/hda3 625 2537 15366172+ 83 Linux
/dev/hda4 2538 7476 39672517+ 5 Extended
/dev/hda5 2538 6500 31832766 83 Linux
/dev/hda6 6501 7476 7839688+ 83 Linux
|
Den første partisjonen tildeles navnet /dev/hda1 og består av alle sylinderne fra 1 til og med
sylinder nummer 608. Hver sylinder er på 8225280 bytes og denne partisjonen er derfor på
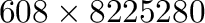 . Alternativt sier output at denne partisjonen består
av 4883728 blocks med størrelse 1024 bytes. Partisjon nr. 2 er en liten swap-partisjon på 16 sylindre og totalt 126 MByte.
Den fjerde partisjonen er spesiell. Det kan bare lages fire såkalte primære partisjoner og om man skal ha flere enn fire må
den fjerde lages som en extended partisjon som inneholder de resterende.
. Alternativt sier output at denne partisjonen består
av 4883728 blocks med størrelse 1024 bytes. Partisjon nr. 2 er en liten swap-partisjon på 16 sylindre og totalt 126 MByte.
Den fjerde partisjonen er spesiell. Det kan bare lages fire såkalte primære partisjoner og om man skal ha flere enn fire må
den fjerde lages som en extended partisjon som inneholder de resterende. /dev/hda4 inneholder ikke data, men definerer
området på disken som utgjør partisjon 5 og 6. Linux-kommandoen df viser hvordan filsystemet er montert på
partisjonene.
for SATA og SCSI-disker heter disk-devicet vanligvis /dev/sda og kommandoen fdisk /dev/sda på en linux PC kan gi:
Disk /dev/sda: 298,1 GiB, 320072933376 bytes, 625142448 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xcb46d2fa
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 591679487 591677440 282,1G 83 Linux
/dev/sda2 591681534 625141759 33460226 16G 5 Extended
/dev/sda5 591681536 625141759 33460224 16G 82 Linux swap / Solaris
|
og heads, tracks og cylinders er ikke lenger nevnt.
[root]@rex$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda1 4806904 4223584 339136 93% /
/dev/hda3 15124900 13790960 565632 97% /lokal
/dev/hda5 31333024 22349088 7392300 76% /mysql
/dev/hda6 7716496 2785908 4538604 39% /mln
|
Alt som ligger under /lokal i filsystemet vil fysisk ligge på partisjon nummer 3. Tilsvarende
for partisjon 5 og 6. Resten av filsystemet, alt annent under / ligger på 1. partisjon.
Neste disk vil het /dev/hdb og på samme måte kan denne deles inn i partisjoner og andre deler av
filsystemet kan monters på disse partisjonene.
Om man deler opp en disk under Windows, tildeles hver partisjon bokstaver, C, D, E etc. Bokstavene A og B er
tradisjonelt satt av for to diskett-stasjoner. Om man har flere disker kan hele denne eller deler av den om man
lager flere partisjoner, tildels andre bokstaver. På Windows XP kan man Ved å kjøre programmet Diskpart se på og endre
partisjoneringen av diskene:
C:\>Diskpart
Microsoft DiskPart version 1.0
Copyright (C) 1999-2001 Microsoft Corporation.
On computer: DIRAC
DISKPART> list disk
Disk ### Status Size Free Dyn Gpt
-------- ---------- ------- ------- --- ---
Disk 0 Online 75 GB 0 B
Disk 1 Online 75 GB 54 GB
|
Denne PC-en har to disker og ved å velge en av diskene kan man se hvilke
partisjoner den inneholder:
DISKPART> select disk 0
Disk 0 is now the selected disk.
DISKPART> detail disk
WDC WD800BB-32BSA0
Disk ID: 3E423E41
Type : IDE
Bus : 0
Target : 0
LUN ID : 0
Volume ### Ltr Label Fs Type Size Status Info
---------- --- ----------- ----- ---------- ------- --------- --------
Volume 2 C NTFS Partition 39 GB Healthy System
Volume 3 F Partition 35 GB Healthy
|
Vi ser at disken er delt i to omtrent like store partisjoner, at den første heter C, er systemdisken og
har filsystemet NTFS. Den andre heter F og på denne er det ennå ikke lagd noe filsystem.
Et multitasking OS vil fortløpende ha behov for å
lese data fra mange forskjellige steder på en disk. Siden disken snurrer rundt er det ikke opplagt hva som er den hurtigste
måten å lese for eksempel 20 forskjellige slike forespørsler. En forespørsel består typisk av tre tall; [leshode, track, sektornummer].
Å flytte lesehodet til nærmeste neste track som skal leses er en
mulighet, å la leshodet flytte seg hele veien fra innerst til ytterst og plukke opp forespøsler underveis er en annen. OS må
velge en slik algoritme for å hente inn data. På moderne disker utføres slike algoritmer av mikroprosessoren som sitter på
diskens egen disk controller. Tidligere tok OS seg direkte av lesingen av data og administreringen av disken, men det ordner
nå disk controlleren.
Før var det også vanlig at OS detaljstyrte skrivingen av data fra disken til internminnet. Dette krevet veldig mange interrupts
hver gang det komm inn data fra disken og derfor bruker moderne systemer DMA (Direct Memory Access) som avlaster denne jobben
for CPU-en. Dette er vanligvis en egen chip knyttet til systembussen med en egen liten mikroprosessor og tillatelse fra CPU til
å skrive direkte til minnet. CPU kan dermed be DMA om en større eller mindre lese eller skriveoperasjoner og
DMA vil administrere kopieringen mellom disk
og internminnet. Først når alle dataene er på plass sender DMA et interrupt til CPU som forteller at kopieringen er
fullført. DMA brukes også for lesning av data fra andre enheter som CD-spiller, USB-devicer etc.
Også for I/O enheter som harddisker som er svært langsomme sammenlignet med internminnet, er det nyttig å bruke
cache. I internminnet er det satt av plass til disk-cache, slik at mest mulig av det som er lest i det siste meelomlagres og
kan hentes ut mye hurtigere om det kommer en ny forespørsel.
15.11 KiB, MiB og GiB
Benenvninger som KB og MB er ikke alltid entydge, KB kan bety både 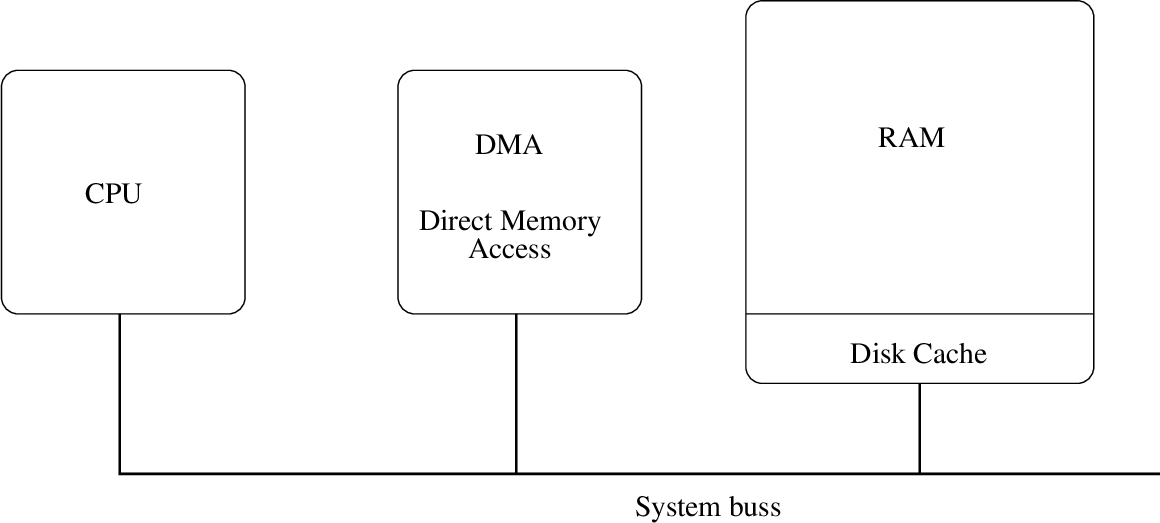 bytes og 1000 bytes.
Den opprinnelige SI6-definisjonen
av prefiksene er den helt korrekte og sier at K = 1000, M = 1000.000, G = 1000.000.000, etc.
Vanlig praksis når det for eksempel gjelder RAM er at 128MB
betyr
bytes og 1000 bytes.
Den opprinnelige SI6-definisjonen
av prefiksene er den helt korrekte og sier at K = 1000, M = 1000.000, G = 1000.000.000, etc.
Vanlig praksis når det for eksempel gjelder RAM er at 128MB
betyr
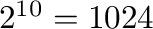 bytes. Men hvis en harddisk-produsent oppgir
at en disk er på 300 GB, betyr det at den er
bytes. Men hvis en harddisk-produsent oppgir
at en disk er på 300 GB, betyr det at den er
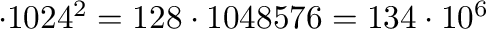 bytes og et OS vil da typisk
rapportere den som en disk med kapasitet på 279.4 GB. For å ordne opp i dette og flere lignende tilfeller av
flertydighet definerte i 1999 International Electrotechnical Commission (IEC) nye binære prefikser
kibi-, mebi-, gibi- og tilhørende symboler Ki, Mi, Gi. Disse prefiksene symboliserer potenser av 2 slik
at
I 2005 ble dette en
IEEE7-standard.
bytes og et OS vil da typisk
rapportere den som en disk med kapasitet på 279.4 GB. For å ordne opp i dette og flere lignende tilfeller av
flertydighet definerte i 1999 International Electrotechnical Commission (IEC) nye binære prefikser
kibi-, mebi-, gibi- og tilhørende symboler Ki, Mi, Gi. Disse prefiksene symboliserer potenser av 2 slik
at
I 2005 ble dette en
IEEE7-standard.
| Navn |
Symbol |
Verdi |
Eksempel |
|---|
| kilo |
K |
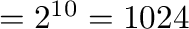 |
|
| mega |
M |
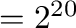 |
|
| giga |
G |
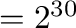 |
|
| tera |
T |
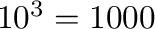 |
|
| kibi |
Ki |
|
100 KB = 97.6 KiB |
| mebi |
Mi |
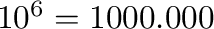 |
100 MB = 95.4 MiB |
| gibi |
Gi |
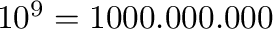 |
100 GB = 93.1 GiB |
| tebi |
Ti |
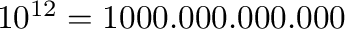 |
100 TB = 90.9 TiB |
Et disk-eksempel viser at produsenten Seagate bruker SI-benvening og sier at en disk er på 160 GB. På
første figur ser man at Linux fdisk bruker samme benevning og 1 GB = 1 milliard bytes.
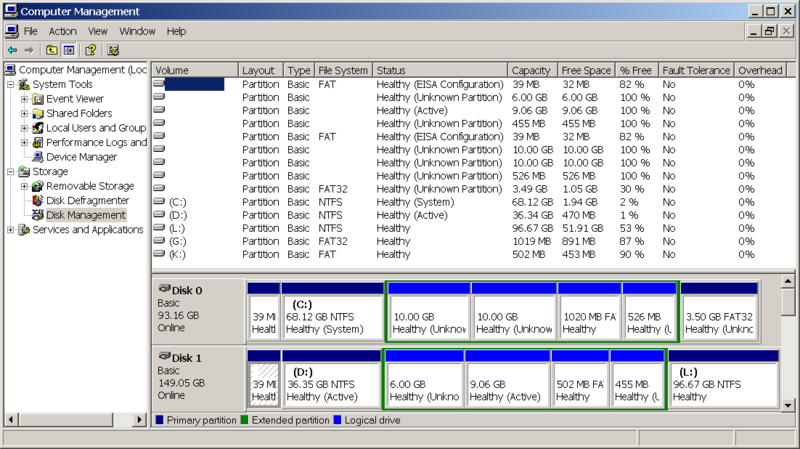
Derimot viser XP's Disk Managment at disken er på 149.05 GB og bruker altså 1 GB = 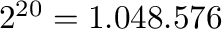 bytes = 1.08 milliarder bytes.
bytes = 1.08 milliarder bytes.
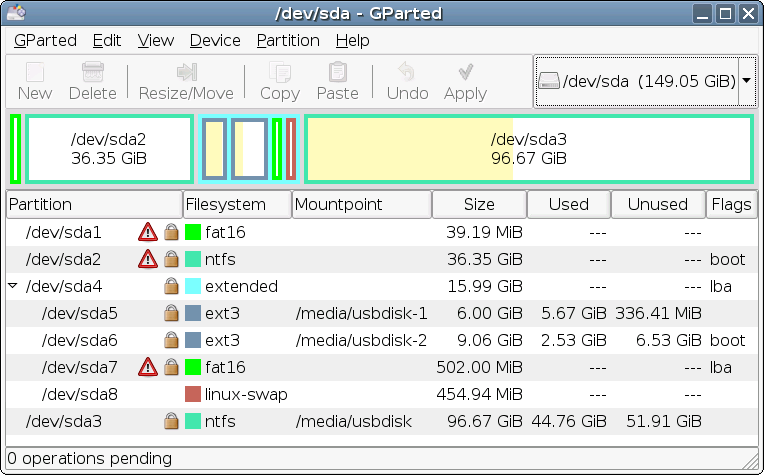
Partisjoneringsverktøyet GParted som brukes under Ubuntu-installasjon, rapporterer disk-størrelser
i GiB, slik at det er helt entydig hva som menes. Men fortsatt er MiB og GiB relativt sjelden i bruk.
Mens utviklingen av hastigheten til prosessorer, cache og delvis RAM har gått raskt, har utviklingen
av hastigheten til harddisker vært langsom. En måte å forbedre ytelsen på når det begynner å bli vanskelig å få hver
enklet enhet til å gå raskere, er å bruke flere enheter i parallell. Utviklingen av multicore prosessorer er et eksempel
på dette. For disker kalles teknologien som gjør dette RAID (Redundant Array of Independent Disks). Man bruker da flere like
disker til å øke hastigheten man kan hente data og man kan også bruke et slikt oppsett til redundans; dobbel lagring av data
slik at man ikke mister data om en disk blir ødelagt.
- RAID 0
- Minst to disker. Striper diskene. Ingen redundans. Hurtigere å lese.
- RAID 1
- Minst to disker. Dupliserer dataene. Hurtigere å lese. Kan fortsatt lese alt om en disk ryker.
- RAID 3
- Minst tre disker. Parallell aksess, veldig små striper, ned til en byte. Paritet lagres på en ekstra disk. Om en disk ryker kan informasjonen hentes ut fra de som er igjen. Optimalt høy overføringshastighet, men kun en forespørsel kan behandles av gangen.
- RAID 4
- Minst tre disker. Paritet lagres på en ekstra disk. Store striper, sektor eller blocks. Om en disk ryker kan informasjonen hentes ut fra de som er igjen. Kan behandle flere forespørsler samtidig. Bra for servere som får mange forespørsler.
- RAID 5
- Minst tre disker. Paritet lagres fordelt på diskene. Store striper, sektor eller blocks. Om en disk ryker kan informasjonen hentes ut fra de som er igjen.
RAID kan implementeres i software, det vil si av OS, eller i hardware ved en dedikert RAID-controller på hovedkortet.
RAID 0, 1 og 5 er implementert i Windows 2003 server.
Ved såkalt striping av diskene økes ytelsen ved både lesing og skriving av filer. Dette fordi en stor
fil deles i striper som fordeles på diskene. Innholdet av en stor fil vil være fordelt på alle diskene og
data kan både leses fra og skrives til diskene i parallell og da går det mye raskere.
Hvis man har en samling bits (for eksempel en byte, 8 bit) som har verdi en eller null, kan man
telle antall enere. Hvis antall enere er like (0, 2, 4, ...), har samlingen av bits like paritet.
Hvis antall enere er odde (1, 3, 5, ...), sier vi at samlingen av bits har odde paritet. Dette kan
brukes til en meget enkel feilsjekking, hvis man sender et antall bit over et nettverk og pariteten har
endret seg på veien, kan man konkludere med at minst ett bit må ha endret verdi. I et RAID kan man
ta et bit fra hver data-disk i RAID'et, regne ut pariteten og skrive den til en egen paritetsdisk.
Hvis en av diskene i RAID'et crasher og alle dataene for denne disken går tapt, kan man bruke dataene på
paritetsdisken for å finne ut verdien på de tapte bit'ene. Hvis pariteten for de igjenværende
diskene er den samme som den lagrede pariteten, har en null gått tapt.
Hvis pariteten for de igjenværende diskene er forskjellig fra den lagrede pariteten, har en ener gått tapt.
Dermed kan hver bit på den tapte disken gjenskapes. I RAID 3 er stripene små, ned til en byte. I RAID 4 og 5
er stripene et antall sektorer. I begge tilfeller er prinsippet for redundans det samme. Bergningen av paritet må
gjøres når det skrives til diskene. Det kan gjøres hurtig, fordi XOR-porter kan regne ut paritet i paralell for
32 eller 64 bit av gangen, for henholdsvis 32 og 64 bits prosessorer. Det finnes også hardware-RAID, egne enheter
som gjør disse paritetsberegningene og styrer RAID'et uavhengig av prosessoren.
Anta at vi i et RAID 3 striper disken bit for bit og bruker 5 disker.
Disken med paritet lagrer da den samlede pariteten for bit'ene for de 4 andre
diskene; en ener om antallet er odde og en null om antallet er like:
| disk 1 |
disk 2 |
disk 3 |
disk4 |
paritets-disk |
|---|
| 0 |
1 |
0 |
1 |
0 |
| 1 |
0 |
1 |
1 |
1 |
| 0 |
0 |
1 |
1 |
0 |
| 1 |
1 |
0 |
0 |
0 |
| 0 |
0 |
1 |
0 |
1 |
| 1 |
1 |
1 |
1 |
0 |
Hvis nå for eksempel den 2. disken crasher og alle dataene fra den blir borte, vil
RAID'et se slik ut:
| disk 1 |
disk 2 |
disk 3 |
disk4 |
paritets-disk |
|---|
| 0 |
|
0 |
1 |
0 |
| 1 |
|
1 |
1 |
1 |
| 0 |
|
1 |
1 |
0 |
| 1 |
|
0 |
0 |
0 |
| 0 |
|
1 |
0 |
1 |
| 1 |
|
1 |
1 |
0 |
Hvordan kan man nå trylle frem igjen dataene på den ødelagte disk2 og
legge dem inn på en ny disk?
Vi ser da at dataene fra denne disken kan trylles frem igjen ved å
bruke paritetsdisken og reglene nevnt over: Hvis pariteten for de igjenværende
diskene er den samme som den lagrede pariteten, har en null gått tapt.
Hvis pariteten for de igjenværende diskene er forskjellig fra den lagrede pariteten, har en ener gått tapt.
Prøv selv!
Hårek Haugerud 2026-04-21

![\includegraphics[width=8cm]{osnotater/slides/OSfig/osaTrack.eps}](img104.png)
![\includegraphics[width=8cm]{osnotater/slides/OSfig/osaSylinder.eps}](img105.png)
![\includegraphics[width=12cm]{fig/filesystem.pdf}](img107.png)
![\includegraphics[width=12cm]{fig/fragmentering.pdf}](img108.png)
![\includegraphics[width=10cm]{fig/11-41.eps}](img111.png)
![\includegraphics[width=10cm]{fig/11-42.eps}](img112.png)
![\includegraphics[width=20cm]{osnotater/slides/OSfig/osaDMA.eps}](img114.png)
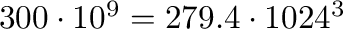
![\includegraphics[width=8cm]{fig/diskSnitt.eps}](img103.png)
![\includegraphics[width=10cm]{osnotater/slides/OSfig/osaPartisjon.eps}](img106.png)