Avsnitt fra Tanenbaum: 1.3.2 - 1.3.7 |
Opptak av forelesningen:
os5time1.mp4
(48:26) Uredigert opptak av første time av forelesningen.
os5time2.mp4
(48:09) Uredigert opptak av andre time av forelesningen.
Opptak av forelesningen inndelt etter temaer:
os5del1.mp4
(03:33) Intro om oblig-innlevering, godkjentkrav for grupper med kun en student, VMer
os5del2.mp4
(01:25) dagens tema, innledning
os5del3.mp4
(14:46) Demo: Optimalisering av maskinkode ved kompilering med gcc -O, fibo()
os5del4.mp4
(03:30) Demo: Optimalisering av SumFunksjon.c med gcc -O
os5del5.mp4
(09:35) Demo: En linje høynivåkode kan bli til flere linjer maskinkode
os5del6.mp4
(05:00) Demo: Assemblykode for enlinje()-funksjonen (NB! Må nå kompileres med gcc -no-pie)
os5del7.mp4
(02:09) Demo: Hva skjer om man prøver å addere to RAM-variabler med en instruksjon?
os5del8.mp4
(02:32) Beskjed fra Ine: vi gir kommentarer til obligene, les dem!
os5del9.mp4
(01:08) Spørsmål: Hva betyr .quad?
os5del10.mp4
(09:01) Tegning og forklaring om CPU, registere og RAM
os5del11.mp4
(18:17) Demo: En if-test i Assembly skrevet fra scratch (NB! Må nå kompileres med gcc -no-pie)
os5del12.mp4
(01:07) Demo: Hvorfor er main() av typen int? Eksempel med returverdi fra C-program.
os5del13.mp4
(01:22) Slides: Forenklinger ved CPU-simuleringen
os5del14.mp4
(01:41) Slides: CPU-løkke (hardware-nivå)
os5del15.mp4
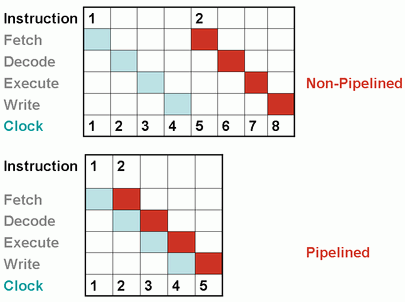
(05:15) Slides: Pipelining
os5del16.mp4
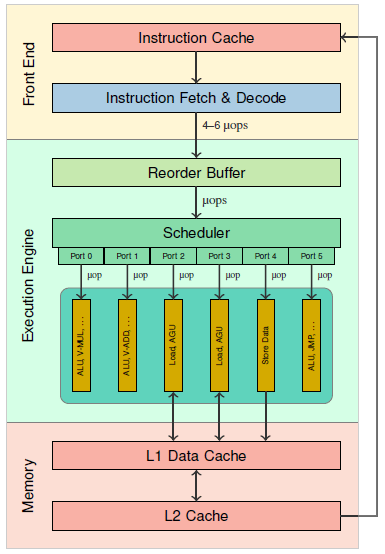
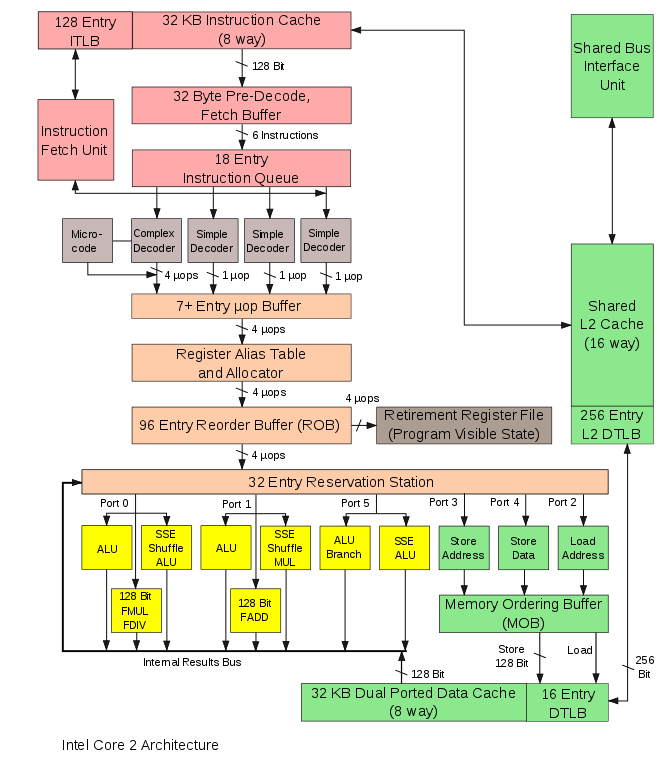
(06:53) Slides: Superscalar arkitektur
Følgende er en C-funksjon som regner ut tall nummer 'last' i Fibinacci-rekken:
int fibo(int last)
{
int i;
int a=1,b=1,c;
/* Har allerede de første to */
for(i=3;i <= last;i++)
{
c = a; /* b skal etterpå få denne */
a = a + b; /* Neste tall */
b = c; /* b fortsatt nest siste tall */
}
return(a);
}
|
Hvis man kompilerer denne koden med gcc -S fibo.c for å se hva slags maskinkode kompilatoren vil lage, får man følgende:
movl %edi, -20(%rbp) movl $1, -12(%rbp) movl $1, -8(%rbp) movl $3, -16(%rbp) jmp .L2 .L3: movl -12(%rbp), %eax movl %eax, -4(%rbp) movl -8(%rbp), %eax addl %eax, -12(%rbp) movl -4(%rbp), %eax movl %eax, -8(%rbp) addl $1, -16(%rbp) .L2: movl -16(%rbp), %eax cmpl -20(%rbp), %eax jle .L3 movl -12(%rbp), %eax popq %rbp ret |
Her kan man se at adderingsoperasjonene utføres direkte på variablene som ligger i RAM, de flyttes ikke først inn i registerne for så å utføre regneoperasjonene
internt inne i CPU-en. Det finnes forøvrig ingen X86-instruksjon som direkte legger sammen to tall som ligger i RAM og så lagrer resultatet i RAM etterpå, derfor må
minst ett av tallene i en addisjon ligge i RAM. Men hvis man istedet kompilerer denne koden med opsjonen -O: gcc -O -S fibo.c får man følgende resultat:
movl $1, %esi movl $1, %ecx movl $3, %edx jmp .L3 .L5: movl %eax, %ecx .L3: leal (%rcx,%rsi), %eax addl $1, %edx movl %ecx, %esi cmpl %edx, %edi jge .L5 rep ret |
Her ser vi at alle beregningene skjer i registerne og dette gir kode som raskere leverer sluttresultatet.
Hvis man gjør dette med vår funksjon, sumFunksjon.c, får man en meget kort Assembly-kode som resultat:
$ gcc -O -S sumFunksjon.c $ cat sumFunksjon.s .file "sumFunksjon.c" .text .globl sum .type sum, @function sum: .LFB0: .cfi_startproc movl $6, %eax ret .cfi_endproc .LFE0: .size sum, .-sum .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits $ |
Hvorfor er koden så kort og hva er den meget effektive beregningen kompilatoren har funnet frem til?
main.c som kaller en ekstern funksjon enlinje():
#include <stdio.h>
extern int enlinje();
int main (void) {
int svar;
printf("Kaller enlinje()...\n");
svar = enlinje();
printf("Svar = %d\n", svar);
}
|
Denne funksjonen, her lagret i filen enlinje.c, legger sammen to variabler som er lagret i RAM og
som heter svar og memvar og returnerer svaret:
int enlinje()
{
int svar = 32;
int memvar = 10;
svar = svar + memvar;
return(svar);
}
|
Vi skal nå se at en enkelt C-instruksjon som linjen
svar = svar + memvar; |
ikke nødvendigvis fører til en enkelt linje med maskinkode. I dette tilfellet er det faktisk ikke mulig å gjøre denne operasjonen med en linje maskinkode, fordi det ikke finnes noen x86-instruksjon som kan utføre denne operasjonen.
Om man prøver å legge sammen to variabler som ligger i internminnet(RAM), slik som dette
add memvar, svar # svar = svar + memvar |
Error: too many memory references for `add' |
Følgende assembly-fil, en.s, inneholder assemblykode som gjøre det samme som enlinje.c:
.globl enlinje # C-signatur:int enlinje () enlinje: # Standard start av funksjon mov memvar, %rbx # Man trenger to linjer kode for å add %rbx, svar # gjøre en høynivålinje svar = svar + memvar mov svar, %rax # Returnerer svar ret # Verdien i rax returneres # Følgende avsnitt av koden viser hvordan man definerer # variabler som lagres i minnet. # Andre linje tilsvarer linjen # int svar=32; # i et C-program # Dette avsnittet kunne også stått øverst i filen .data svar: .quad 32 # deklarerer variabelen svar i RAM memvar: .quad 10 # 8 byte = 64 bit variable |
C-koden main.c i starten av avsnittet kan brukes for å kalle assembly-funksjonen over med
gcc -no-pie main.c en.s |
Hvis man kompilerer enlinje med
gcc -S enlinje.c |
Får man følgende kode:
.file "enlinje.c" .text .globl enlinje .type enlinje, @function enlinje: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $32, -8(%rbp) movl $10, -4(%rbp) movl -4(%rbp), %eax addl %eax, -8(%rbp) movl -8(%rbp), %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size enlinje, .-enlinje .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits |
NB! Fra og med 2022 har default konfigurasjon av kompilatoren gcc endret seg, slik at man nå må legge på opsjonen -no-pie for å kompilerere assembly-kode som deklarere variabler i et data-segment. Derfor må man kompilere med
gcc -no-pie main.c en.s |
gcc -no-pie når man loader sammen en slik kompilert assembly-fil med en
kompilert C-fil. Hvis ikke får du en feilmelding om relocation R_X86_64_32S against '.data' can not be used.
.globl iftest
# C-signatur:int iftest ()
iftest: # Standard start av funskjon
# Returnerer 1 hvis svar > 42, ellers 0
# if(svar > 42){
# return(1):
# }
# else{
# return(0);
#}
mov $42, %rbx
cmp %rbx, svar # compare
jg greater # Jump Greater, hvis svar > 42
mov $0, %rax # 42 eller mindre hvis her
jmp return
greater:
mov $1, %rax
return:
ret # Verdien i rax returneres
.data
svar: .quad 40 # deklarerer variabelen svar i RAM
|
Pseudo-kode for den evige hardware-løkken som CPU-en kjører:
while(not HALT)
{
IR = mem[PC]; # IR = Instruction Register
PC++; # PC = Program counter
execute(IR);
if(InterruptRequest)
{
savePC();
loadPC(IRQ); # IRQ = Interrupt Request
# Hopper til Interrupt-rutine
}
}
|
Eksempel med 4 stages:
| År | arkitektur (CPU) | pipeline stages | Max MHz | nm |
|---|---|---|---|---|
| 1978 | 8086 | 2 | 5 | 3000 |
| 1985 | 486 | 5 | 33 | 1000 |
| 1995 | P6 (Pentium Pro) | 14 | 450 | 250 |
| 2000 | NetBurst (Pentium 4) | 20 | 2000 | 180 |
| 2004 | NetBurst (Pentium 4) | 31 | 3800 | 90 |
| 2011 | Sandy Bridge (core i7) | 14 | 4000 | 32 |
| 2015 | Skylake (core i7) | 14 | 4200 | 14 |
| 2019 | Cascade Lake (core i9) | 14 | 4400 | 14 |