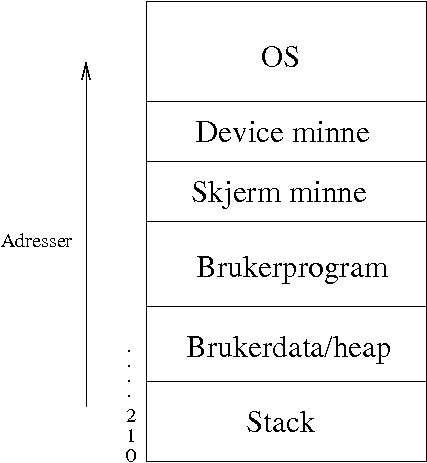
 Stack: brukes bl. a. til å lagre adressen som skal returneres til ved subrutinekall.
Stack: brukes bl. a. til å lagre adressen som skal returneres til ved subrutinekall.
Avsnitt fra Tanenbaum: 1.3-1.6 |
os6time1.mp4
(43:50) Uredigert opptak av første time av forelesningen.
os6time2.mp4
(54:03) Uredigert opptak av andre time av forelesningen.
Opptak av forelesningen inndelt etter temaer:
os6del1.mp4
(05:05) Praktisk info, MC1, oblig2
os6del2.mp4
(03:31) Intro om Linux-VMer (Docker containere)
os6del3.mp4
(07:10) Demo: Innlogging på Linux-VMer (Docker containere)
os6del4.mp4
(02:04) Intro, hva vi gjorde sist
os6del5.mp4
(08:08) Slides: Branch prediction og Meltdown
os6del6.mp4
(13:19) Demo: branch prediction i praksis
os6del7.mp4
(04:21) Spørsmål, hvordan få os-passord og logge seg inn på VM (repetisjon)
os6del8.mp4
(03:06) Slides: Oppsummering av datamaskinarkitektur
os6del9.mp4
(09:29) Slides: OS-historie, Microsoft OS
os6del10.mp4
(02:45) Slides: OS-historie, Unix OS
os6del11.mp4
(09:19) Slides: Intro til multitasking
os6del12.mp4
(06:18) Slides: Context Switch og PCB (Prosess Control Block)
os6del13.mp4
(03:30) Slides: Multitasking i praksis
os6del14.mp4
(08:42) Demo: Multitasking i praksis
os6del15.mp4
(01:09) Spørsmål: Hvilke prosesser er ikke CPU-avhengige?
Følgende C++ program inneholder kode som viser hva konsekvensene av branch prediction kan være. I starten av programmet lages et data-array med tilfeldig trukkede heltall mellom 0 og 255. De 10 første tallene blir skrevet ut og så gjentas en ytre løkke 100.000 ganger for at man skal få mer nøyaktige målinger av hvor lang tid den indre løkken tar. Den indre løkken består av at man går igjennom hvert element i det store arrayet og legger til verdien data[c] til en variable sum hvis verdien er større enn 127. I praksis vil dette skje omtrent halvparten av gangene.
#include <algorithm>
#include <iostream>
using namespace std;
int main()
{
// Lager et data-array
int i,c;
int arraySize = 32768;
int data[arraySize];
for (c = 0; c < arraySize; ++c)
{
data[c] = rand() % 256;
}
// Gir tilfeldig tall mellom 0 og 255
// Gir samme array med tall for hver kjøring
// sort(data, data + arraySize);
// sorterter data-arrayet
// Skriver ut de 10 første verdiene
for (c = 0; c < 10; c++)
cout << data[c] << "\n";
// Legger sammen alle tall større enn 127
long sum = 0;
// Ytre løkke for at det skal ta litt tid...
for (i = 0; i < 100000; ++i)
{
// Indre løkke
for (c = 0; c < arraySize; ++c)
{
if (data[c] > 127)
sum += data[c];
}
}
cout << "sum = " << sum << "\n";
}
|
Deretter kompileres C++ programmet og kjøres på en Linux-maskin:
$ g++ b.cpp $ time ./a.out 103 198 105 115 81 255 74 236 41 205 sum = 314931600000 Real:17.095 User:17.096 System:0.000 100.00% |
time tar tiden på programmet som kjøres og gir som resultat at programmet har brukt 17.096 sekunder CPU-tid og at det har brukt CPU-en hele tiden (100%). Utskriften av de 10 første tallene viser at verdiene kommer i en tilfeldig rekkefølge og at de er over og under 127, slik at if-testen vil slå til en gang i blant og i gjennomsnitt ca halvparten av gangene.
Deretter gjøres en enkelt endring på koden ved at kommentartegnet foran linjen
sort(data, data + arraySize); |
0 0 0 0 0 0 0 0 0 sum = 314931600000 Real:6.285 User:6.280 System:0.000 99.91% |
Intels første 32-bit maskin var 386 fra 1985. Generelt problem før XP: Windows er bakover-kompatibelt til DOS, alle Win-prosesser kan ødelegge for kjernen og ta ned OS.
-> alpha, PowerPC
\winnt\system32\ntoskrnl.exe. 29 millioner
linjer. MS-DOS borte, men 32-bits kommando-interface med samme
funksjonalitet.
| OS | Eier | hardware |
|---|---|---|
| AIX | IBM | RS6000, Power |
| Solaris | Sun | Sparc, intel-x86 |
| HP-UX | Hewlett-Packard | PA-RISC, Itanium(IA-64) |
| Tru64 UNIX(Digital Unix) | HP(Compaq(DEC)) | Alpha |
| IRIX | Silicon Graphics | SGI |
| OS | hardware |
|---|---|
| FreeBSD | x86, Alpha, Sparc |
| OpenBSD | (sikkerhet) x86, Alpha, Sparc, HP, PowerPC, mm |
| NetBSD | x86, Alpha, Sparc, HP, PowerPC (Mac), PlayStation, mm |
| Darwin | (basis for Mac OS X og iOS, kjernen, XNU, bygger på FreeBSD og Mach 3 microkernel) , intel x86, ARM, PowerPC |
| Linux | x86, Alpha, Sparc, HP, PowerPC, PlayStation 3, Xbox, stormaskin, mm |
Basis for flerprosess-systemer.
Stack: brukes bl. a. til å lagre adressen som skal returneres til ved subrutinekall.
For å lage et system som kan kjøre n programmer samtidig, må vi få en enprosess maskin til å se ut som n maskiner.
Bruker software til å fordele tid mellom n programmer og å dele ressurser; minne, disk, skjerm etc. OS-kjernen utfører denne oppgaven.
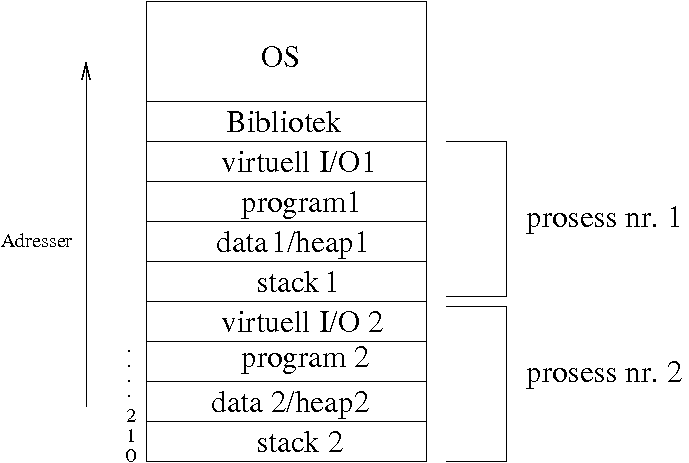
Samtidige prosesser må tildeles hver sin del av minne:
|
|
|
All PCB-info må lagres i en Context Switch -> tar tid -> systemoverhead
Programmet vi bruker er et lite shell-script som står i en løkke og regner og regner. Da vil det hele tiden ha behov for CPU-en. Siden prosessen aldri har behov for å vente på data fra disk, tastatur eller andre prosesser, kan den regne uten stans. Programmet heter regn og ser slik ut:
#! /bin/bash
# regn (bruker CPU hele tiden)
(( max = 100000 ))
(( i = 0 ))
(( sum = 0 ))
echo $0 : regner....
while (($i < $max))
do
(( i += 1 ))
(( sum += i ))
done
echo $0, resultat: $sum
|
lscpu kan man hente ut mye nyttig informasjon om cpu og cache:
user@chokeG7:~$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 40 bits physical, 48 bits virtual CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 NUMA node(s): 1 Vendor ID: AuthenticAMD CPU family: 15 Model: 65 Model name: Dual-Core AMD Opteron(tm) Processor 2216 Stepping: 3 CPU MHz: 2400.114 BogoMIPS: 4800.22 Hypervisor vendor: Xen Virtualization type: full L1d cache: 64K L1i cache: 64K L2 cache: 1024K NUMA node0 CPU(s): 0 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt rdtscp lm 3dnowext 3dnow rep_good nopl cpuid extd_apicid pni cx16 x2apic hypervisor lahf_lm cr8_legacy 3dnowprefetch vmmcall |
Dette viser at denne Linux-maskinen har èn enkelt 64-bits CPU med en klokkefrekvens på 2.4 GHz. Utskriften viser også at dette er en virtuell maskin, man kan se at den er virtualisert med Xen utifra de to linjene
Hypervisor vendor: Xen Virtualization type: full |
Videre kan man se størrelsen på L1 og L2 cache. En rask og tydelig oversikt kan man få med kommandoen lstopo:
lstopo --no-io |
som gir følgende figur
Vi starter en instans av programmet regn som er CPU-intensivt og bruker så mye CPU det kan få:
mroot@chokeG7:~$ ./regn ./regn, resultat: 3125001250000 |
Samtidig startes top og man kan se at prosessen med PID (Process ID) 18908 forsyner seg grovt av CPU-en og klarer å karre til seg 99.3% av CPU-tiden. Verdien som vises er gjennomsnittsverdien for de siste 3 sekunder.
top - 14:32:39 up 10 days, 23:56, 2 users, load average: 0,09, 0,12, 0,05 Tasks: 74 total, 1 running, 73 sleeping, 0 stopped, 0 zombie %Cpu(s): 0,0 us, 0,7 sy, 0,0 ni, 99,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,3 st PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18908 mroot 20 0 9504 3244 3008 R 99,3 0,7 0:07.16 regn 18903 mroot 20 0 16668 4668 3536 S 0,3 1,0 0:00.04 sshd |
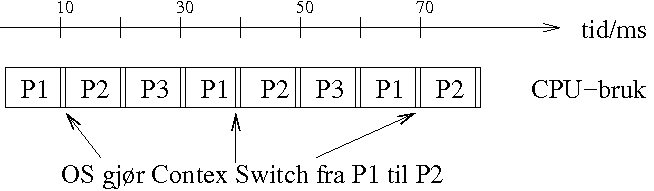
Vi starter så en instans til av programmet som regner i vei, uavhengig av den første. Da ser vi at OS fordeler CPU-en likt mellom de to prosessene og de får i underkant av 50% hver av CPU-tiden.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18912 mroot 20 0 9504 3224 2988 R 49,8 0,7 0:13.14 regn 18913 mroot 20 0 9504 3312 3080 R 49,8 0,7 0:12.84 regn |
Dette betyr at reelt sett er det til enhver tid bare en prosess som kjører, men det oppleves som om de kjører samtidig fordi OS deler opp tiden i små biter(1-10 hundredels sekunder) og lar dem bruke CPU-en annenhver gang. Husk at for en prosess er ett hundredels sekund lang tid, den kan rekke å utføre millioner av maskininstruksjoner på den tiden.
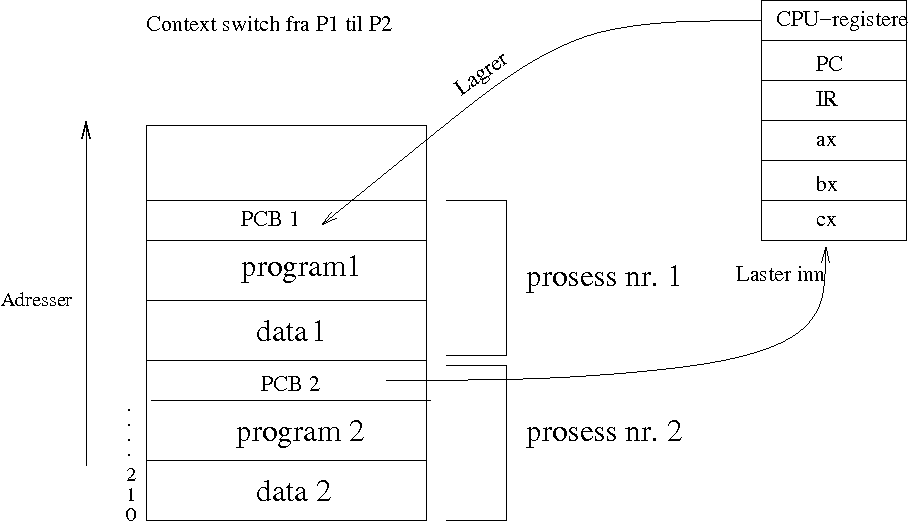
![\includegraphics[width=11cm]{fig/multitasking.pdf}](img60.png)
![\includegraphics[width=4cm]{fig/1cpu.pdf}](img61.png)