Subsections
Slides brukt i forelesningen
Uredigert opptak av hele første time av forelesningen ( 00:44:25)
Uredigert opptak av hele andre time av forelesningen ( 00:55:46)
os13del5.mp4
(07:59) Slide: Internminne og Cache
os13del6.mp4
(03:21) Slides: Minnepyramiden, Internminnet
os13del7.mp4
(00:07) Slide: Adresserommet
os13del8.mp4
(07:21) Slides: Virtuelt adresserom
os13del9.mp4
(01:26) Spørsmål: Hva er GDDR? Graphics DDR som brukes sammen med GPU-er
os13del10.mp4
(03:33) Spørsmål: Hva slags registere lagrer adresser? Vanlige CPU-registere. Demo av hvordan det ser ut i simulerings-CPUen
os13del11.mp4
(09:52) Slides: Virtuelle (logiske) adresser, Internminnet og kompilering, linking og loading
os13del12.mp4
(08:10) Demo: Generering og bruk av statisk og dynamisk bibliotek i C++
os13del13.mp4
(01:30) Slide: Linux-prosess segmentation
os13del14.mp4
(05:56) Slides: Minneadressering og MMU med lite eksempel
os13del15.mp4
(05:41) Slides: Paging, pages og page table entry
os13del16.mp4
(04:43) Slides: TLB - Translation Lookaside Buffer, ytelse og TLB-cache
os13del17.mp4
(05:54) Slides: Konkret eksempel med MMU-oversettelse med 64K virtuelt og 32K fysisk internminne
os13del18.mp4
(02:25) Slides: Paging og swapping, paging-algoritmer
os13del19.mp4
(01:04) Spørsmål: Er load 32 den designerte start-adressen? Ja, dette er en virtuell adresse som må oversettes
os13del20.mp4
(01:03) Spørsmål: Hva om en prosess bruker adresse som ikke er egne? Segmentation fault
os13del21.mp4
(03:20) Spørsmål: Hvorfor lager man ikke større L1, for eksempel 1 GB?
Om internminnet bruker man ofte betegnelsen RAM som er en forkortelse for Random Access Memory. Det kalles 'Random' fordi hvilken som helst byte kan leses ut eller aksesseres like raskt som enhver annen byte. Men som vi skal se vil det i praksis ikke alltid stemme at det tar like lang tid å laste inn to forskjellige byte fra RAM. En årsak til dette som gjelder for de aller fleste systemer er cache som mellomlagrer data. Hvis vi henter inn verdine på en variabel og denne ligger i cache, går inntil ti ganger raskere enn om den må hentes helt fra RAM. En annen årsak som gjelder større servere er at servere med flere titalls CPU-er ofte er delt inn i såkale numanodes som kommuniserer raskere med enkelte tilordnede deler av RAM. Dette kan utgjøre en hastighetsforskjell på inntil to tre ganger.
Vi så i avsnitt 7.3 at både CPU-registre og cache er laget av SRAM (Static RAM), men det er ikke en del av internminnet. Aksess til SRAM er ekstremt hurtig og SRAM er statisk i den betydning at det ikke trenger å oppfriskes. Internminnet er laget av DRAM som står for Dynamic RAM. Mer en 10 ganger i sekundet må DRAM opplades, ellers forsvinner informasjonen. SRAM består av 6 transistorer for hver bit som lagres. Men DRAM trenger bare en transistor og en kapasitator(lagrer elektrisk ladning) for å lagre en bit. Derfor er DRAM billigere, mindre, bruker mindre effekt og kan lages i større enheter. Internminnet består derfor av DRAM eller forbedrede varianter av DRAM. DDR5 SDRAM (Double-Data Rate generation 5 Synchronus Dynamic RAM) er et av de foreløpig siste leddene av kjedene av forbedrede utgaver av DRAM.
I samme avsnitt viste Fig. 78 noen typiske størrelser og aksesstider for de sentrale lagringsmedien som finnes i en datamaskin, fra registre til harddisk. Legg spesielt merke til den store forskjellen i aksesstid mellom internminnet og harddisk, selv moderne superraske SSD-disker er tusen ganger tregere.
Internminnet (RAM, Random Access Memory/arbeidsminne) er et stort array av bytes:
Alle disse adressene utgjør tilsammen det fysiske minnet siden det er adresser til fysisk DRAM enheter som lagrer bit.
I følgende tabell kan man se hvor mange adresser det er plass til for forskjellige størrelser av registre. Det totalet antall adresser som finnes for en gitt størrelse av et register kalles et adresserom.
| Registerstørrelse (i bit) |
antall mulige adresser |
|---|
| 16 |
 = 64 K, Kilo, = 64 K, Kilo, 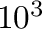 |
| 32 |
4 G, Giga, 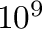 |
| 48 |
256 T, Tera, 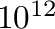 |
| 64 |
20 E,Exa, 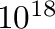 |
Generelt er det ikke plass til alle programmer i internminnet på en gang. Derfor gir man hvert
enkelt program sitt eget virtuelle adresserom fra 0 til det programmet måtte trenge. Er adresse-registeret 32 bit,
er typisk det virtuelle adresserommet opp til 4Gbyte. Det vil da virke for prosessen som den har tilgang til
alt dette minnet. Men i virkeligheten er ikke nødvendigvis alt i bruk og av det som er i bruk kan noe ligge i RAM og andre deler på disk.
Disse virtuelle eller logiske adressene brukes overalt hvor programmet refererer til seg selv, for eksempel i en instruksjon som
som betyr last inn byte nummer 1023 i det 8 bit store registeret %al. 1023 er da den virtuelle adressen.
Når programmet lastes inn
i internminnet og kjøres vil det variere hvor i det fysiske minnet programmet legges. Det må derfor være mulig
å oversette mellom virtuelle og fysiske adresser.
Et kjørbart program ligger i utgangspunktet på harddisken, men må lastes inn
i internminnet før det kan kjøres.
Skjematisk må kildekode gjennom prosessen i Fig. 69 før den kan kjøres.
Hvis man lager C++-prosjekter og har metoder man ofte bruker, kan man lage sin egen
library-fil som man kobler sammen med hovedprogrammet når man skal bruke det.
Kompileringen av biblioteksfilen kan se slik ut:
g++ -c calcTools.cpp # Lager maskinkode calcTools.o
g++ -c randTools.cpp # Lager maskinkode randTools.o
ar rcv libTools.a calcTools.o randTools.o # Lager lib-filen libTools.a
|
Senere kan dette biblioteket brukes i et prosjekt:
g++ -c -I../Tools mainsim.cpp # Lager maskinkode mainsim.o
g++ -c -I../Tools simulation.cpp # Lager maskinkode simulation.o
g++ -c -I../Tools user.cpp # Lager maskinkode user.o
g++ -o sim mainsim.o simulation.o user.o -lm -L../Tools -lTools
sim # Kjører programmet
|
Dette linker (limer sammen) de 3 programmene med libTools.a (som loaderen finner pga -L../Tools) og
andre biblioteker (-lm tar med et matte-bibliotek) og lager en kjørbar fil med navn sim.
Man kan også lage et dynamisk (shared) library med filendelse so.
g++ -fpic -c randTools.cpp
g++ -fpic -c calcTools.cpp
g++ -shared -o libsTools.so randTools.o calcTools.o
g++ -o sim mainsim.o simulation.o user.o -lm -L../sTools -lsTools
export LD_LIBRARY_PATH="../sTools"
sim # Kjører programmet
|
Det virtuelle adresserommet til en prosess er delt opp i regioner eller segmenter og de følgende er de viktigste:
- Den statiske binære koden som prosessen kjører, text segmentet, ofte bare kalt text
- Heap`en hvor globale variabler og data som dynamisk generers lagres
- Stack`en hvor de lokale variablene lagres, brukes også til funksjonskall
- MMAP, minneavbildninger av filer(og devicer) på disk direkte i det virtuelle minnet
Et programs virtuelle adressering til variabler, subrutiner, bibliotek, data og så videre
må knyttes til fysiske adresser. Dette kunne skjedd ved loading, men ville vært svært tidkrevende og tungvint.
I moderne OS
gjøres dette dynamisk mens programmene kjører. Dette muligjør at programmer og biblioteker
kan flyttes til og fra harddisk og bare loades når det er behov for dem.
Om OS skulle oversette fysiske adresser til logiske/virtuelle, ville det belaste CPU-en for mye, så
dette tar en egen enhet, MMU (Memory Managment Unit), seg av.
Anta at de to programmene Prog1 og Prog2 skal kjøre på en maskin. Som i Fig. 72
vil adressene i de kompilerte programmene være logiske og ikke til en fastlagt adresse i minne.
Dette fordi man da bare trenger å oppdatere MMU-tabellene når programmene plasseres eller omplasseres i RAM.
Når CPU utfører instruksjonen 'load 32' for Prog1 som refererer til minnet sendes
den logiske adressen 32 til MMU som bruker sin tabell for Prog1-adresser til å oversette til
den fysiske adressen 132, slik at riktig byte blir loadet. MMU trenger da tabeller som
ser slik ut:
| Prog1 |
Prog2 |
|---|
| 0 |
100 |
0 |
150 |
| . |
. |
. |
. |
| . |
. |
. |
. |
| 24 |
124 |
28 |
178 |
| . |
. |
. |
. |
| . |
. |
. |
. |
| 32 |
132 |
36 |
186 |
| . |
. |
. |
. |
| 40 |
140 |
40 |
190 |
Men det vil være alt for minnekrevende å ha en linje i tabellen for
hver adresse! Det logiske minnet deles derfor opp i pages som legges
i det fysiske minnet hver for seg. I eksempelet over kunne en page
f. eks. utgjøre 50 adresser. MMU trengte da bare å vite at Prog1
starte på adresse 100 og at Prog2 startet på adresse 150.
Ved å dele inn minnet i like store biter (pages/sider), vil man effektivt kunne laste disse sidene
inn og ut av minnet og samtidig enkelt holde oversikt over hvor hver side er i en page-tabell. Dette gjør at det er
enkelt og plassbesparende å dynamisk allokere (sette av) nytt minne til en prosess. Man unngår den fragmentering som ville
oppstått om vilkårlig store biter av minnet ble tildelt en prosess. Når prosessen ble avluttet, ville det da blit et hull
med tilgjengelig med akkurat denne størrelsen. Ved å bruke faste sidestørrelser, unngår man slike ujevnt store hull.
Inndelingen i sider gjør at deler av programmer effektivt kan lastes inn og ut av minnet og dermed
gjør det enkelt å implementere virtuelt minne. En viktig fordel for OS er at med full oversikt over en prosess sitt minnet i en
page-tabell, er det lett å kontrollere at prosessen bare skriver til det minnet den er tildelt. Oppsummert har
bruk av logiske eller virtuelle minneadresser og inndeling av disse i sider av samme størrelse har følgende fordeler:
- Fast sidestørrelser hindrer fragmentering
- Dynamisk flytting av deler av prosesser til og fra disk
- Full kontroll for OS over prosessers minnebruk
- Mulliggjør å bruke diskplass til å utvide minnet, virtuelt minne
En page har en størrelse 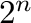 bytes og typisk er n = 12 eller 13 og
page-størrelsen er dermed 4 eller 8 Kbytes. Den konkrete størrelsen avhenger av prosessorens arkitektur.
4Kbytes er vanlig for X86-prosessorer. Figur 73 hviser et eksempel på
hvordan pages kan fordeles i minnet og hvor enkel MMU-tabellen da blir. Ved en context switch
lagres tabellen for den gamle prosessen i dens PCB og tabellen til den nye prosessen
lastes inn i MMU.
bytes og typisk er n = 12 eller 13 og
page-størrelsen er dermed 4 eller 8 Kbytes. Den konkrete størrelsen avhenger av prosessorens arkitektur.
4Kbytes er vanlig for X86-prosessorer. Figur 73 hviser et eksempel på
hvordan pages kan fordeles i minnet og hvor enkel MMU-tabellen da blir. Ved en context switch
lagres tabellen for den gamle prosessen i dens PCB og tabellen til den nye prosessen
lastes inn i MMU.
En prosess som bruker 100Mbyte minne vil med 4Kbyte page størrelse bestå av omtrent 25.000 sider men en prosess som bruker 4GByte RAM vil ha en million sider i MMU. Det er ikke plass til å lagre
adressen til alle disse sidene i selve MMU og den fullstendige tabellen ligger selv i internminnet. Men MMU bruker en
Translation Lookaside Buffer (TLB) som er hurtig cache minne som inneholder en del av page-tabellen. Ved oppslag på adresser til
sider som ikke ligger her, hentes de fra minnet, men da tar det vesentlig lenger tid.
I Figur 74 som er hentet fra Tanenbaum, ser man et eksempel på en avbilding fra det virtuelle 64K store virtuelle adresserrommet til det 32K store fysiske adresserommet. Vanligvis er begge adresserom mye større. Og man må huske at hver prosess får tildelt sitt eget adresserom og dette peker på fysiske adresser i RAM. Andre prosesser vil da peke til andre steder i RAM. Hver gang det gjøres en context switch og en annen prosess starter å kjøre på en CPU, må denne prosessens MMU-tabell lastes inn før den kan begynne å kjøre. Dette er eksempel på en slik tabell etter at den er lastet inn. Vi ser at det er åtte (0-7) virtuelle pages som peker på åtte fysiske page-frames i RAM.
Når MMU mottar en innkommende virtuell adresse, 8196 i eksempelet i Figur 75, må denne adressen ekstremt hurtig oversettes til en fysisk adresse. I dette tilfellet er side-størrelsen 4K og 12 bit vil da kunne brukes til å adressere hele siden. Det virtuelle adresserommet er på 64k og man trenger da 16 bit for å adressere hele dette adresserommet.
Vi ser at de fire første bit'ene brukes til å angi hvilket nummer i rekken av 16 pages som en adresse hører til. I eksempelet er de fire første bit'ene 0010 = 2 og det betyr dermed virtuell page nr. 2. MMU-tabellen viser hvilken fysisk frame hver av de 16 virtuelle sidene peker på og vi ser at page 2 peker på fysisk frame nummer 110 = 6. Dette kan vi også se i Figur 73, der en pil viser at page nummer 2 peker på fysisk frame nummer 6 (man starter å telle på null). Oversettelsen skjer lynraskt ved at de tre bit'ene i indeks 2 i MMU-tabellen, 110, hektes på foran de 12 bit'ene som forteller hvor i den 4K store framen byte'en som ønskes ligger. Dette gir dermed øyeblikkelig den utgående adressen 24580. Det fysiske adresserommet er på 32k og 15 bit er da nok til å dekke hele adresserommet.
Hver page har 2^12 = 4096 adresser. Page 0 begynner på 0, page 1 begynner på 4096, page 2 begynner på 8192 og så videre. Inkommende adresse er 8196, fordi den er 2x4096 (første byte page 2, 0010) + offset 4 (100) som tilsammen blir 8192 + 4 = 8196. Den utgående adressen til fysisk frame blir 24580, fordi den er 6*4096 (første byte page 6, 110) + offset 4 (100) som tilsammen blir 24576 + 4 = 24580.
Å dele in det logiske minnet i pages gjør det mulig å dynamisk laste inn og ut deler av en
prosess. Dermed kan minnet til det samlede antall prosesser på en maskin være
større enn det fysiske minnet, resten lagres page for page på harddisk på swap-området.
Det virtuelle minnet til en prosess kan da fysisk lagres både i RAM og på disk. I Fig. 77 har fysisk minne
bare plass til 3 pages og resten må lagres på disk. Det å laste pages til og fra swap-området
på disken kalles "paging".
Figure:
![\includegraphics[width=12cm]{fig/virtuelt.eps}](img102.png)
g
|
Tidligere var swapping eneste måte å bruke disk til virtuelt minne; da blir hele prosessen lastet ut på disk.
Med en disk med lesehastighet på 100MByte/s tar det 10 sekunder å swappe en prosess på 1 GByte.
Swapping brukes i moderne OS oftest bare når det er ekstrem mangel på minne. Er det fysiske
minnet altfor lite, vil OS bruke nesten all sin tid på å flytte sider til og fra disk; dette
kalles trashing. Det er viktig å huske at det kan ta flere hundere tusen ganger så lang tid å hente
pages fra en disk som å aksessere RAM, så virtuelt minne kan på ingen måte fullt ut erstatte RAM.
Figure:
![\includegraphics[width=12cm]{fig/pageEntry.pdf}](img103.png)
g
|
- Page Frame nummer: Fysisk frame-nummer i RAM
- Present: Hvis 0 blir det en page-fault
- Endret: Hvis 1 er siden dirty og må skrives til disk om den fjernes
- Rettigheter: lese, skrive, kjøre
- Referenced: settes hvis brukt, brukes av paging-algoritmer
- En prosess som bruker 100Mbyte minne vil med 4Kbyte page størrelse bestå av omtrent 25.000 sider
- 4GByte prosess gir en million sider i MMU
- Ikke plass til å lagre adressen til alle disse sidene i MMU
- Den fullstendige tabellen ligger selv i internminnet
- MMU bruker en Translation Lookaside Buffer (TLB) som er hurtig cache minne
- Inneholder en liten del av page-tabellen,
- Ved oppslag på adresser til sider som ikke ligger i TLB, hentes de fra RAM
- Kalles TLB-miss eller soft-miss. Tar vesentlig lenger tid enn om adressen er i TLB
- størrelse: 16 - 4096 linjer (1 - 256 kBytes)
- En cache linje er vanligvis 64 bytes
- oppslagstid: 0.5 - 1 klokke-sykel
- ekstra tid ved TLB-miss: 10-100 klokke-sykler
- TLB-miss frekvens: 0.01 - 1%
Vi har tidligere sett at for å kunne fore en hurtig prosessor med instruksjoner og data raskt nok, bruker man
flere nivåer av mellomlagring av data, såkalt cache-minne. Det går vesentlig
raskere å hente minne fra cache-minnet enn fra internminnet. I Fig. 45 så vi
noen typiske størrelser og aksesstider for de sentrale lagringsmedien som finnes i en datamaskin, fra registre til harddisk.
Spesielt bemerket vi den store forskjellen i aksesstid mellom internminnet og harddisk.
Cache inneholder både data, instruksjoner og deler av MMU page-tables i TLB (Translation Lookaside Buffer). I L1 cache er
ofte disse egne enheter, mens L2 cache pleier å være en enhet. I de senere årene har man klart å få plass til L2 på selve
prosessorchip'en (den lille brikken som utgjør mikroprosessoren, bare noen kvadratcentimeter stor). Arkitekturen til en
moderne prosessor kan da i grove trekk se ut som i Fig. 78.
Noen arkitekturer har
i tillegg enda et lag i minnehierarkiet, en offchip L3 cache som sitter mellom mikroprosessoren og RAM.
For Intel Core i7 og AMD Opteron K10 har også L3 cache fått plass på prosessor-chip'en.
- Page-fault (En page mangler i minnet; ligger på swap på disk)
- Ingen ledig frame i minnet
- OS må velge hvilken page som skal legges på disk
- Gjøres av paging-algoritme
Hårek Haugerud 2025-05-07
![\includegraphics[width=12cm]{fig/osaCache.eps}](img64.png)
![\includegraphics[width=4cm]{fig/minne.eps}](img89.png)
![\includegraphics[width=12cm]{fig/osaCache2.eps}](img66.png)
![\includegraphics[width=12cm]{fig/loading.eps}](img94.png)
![\includegraphics[width=8cm]{fig/memlayout.eps}](img95.png)
![\includegraphics[width=10cm]{fig/MMU.eps}](img96.png)
![\includegraphics[width=10cm]{fig/prog12.eps}](img97.png)
![\includegraphics[width=10cm]{fig/paging.eps}](img99.png)
![\includegraphics[width=10cm]{fig/03-09.eps}](img100.png)
![\includegraphics[width=10cm]{fig/03-10.eps}](img101.png)