![\includegraphics[width=10cm]{fig/lstopo.pdf}](img62.png)
|
Avsnitt fra Tanenbaum: 1.5 - 1.6 |
Opptak av forelesningen:
os7time1.mp4
(43:50) Uredigert opptak av første time av forelesningen.
os7time2.mp4
(54:03) Uredigert opptak av andre time av forelesningen.
Opptak av forelesningen inndelt etter temaer:
os7del1.mp4
(07:03) Velkommen og intro, oppsummering av forrige forelesning
os7del2.mp4
(11:11) Demo: CPU intensiv regnejobb på 1, 2 og 4 CPUer
os7del3.mp4
(02:11) Spørsmål: i top virker det ikke å taste f. Demo på Linux-VM, virker der
os7del4.mp4
(01:28) Spørsmål: Er en regne-enhet en ALU? Ja,...
os7del5.mp4
(02:12) Demo: CPU-fordeling på VM/containere
os7del6.mp4
(06:36) Slides: Internminne og Cache, Minnepyramiden
os7del7.mp4
(02:18) Slides: SRAM og DRAM
os7del8.mp4
(06:00) Slides: L1 og L2 Cache
os7del9.mp4
(03:20) Spørsmål: Hvorfor er ikke Real = User + System for time-kommandoen?
os7del10.mp4
(01:14) Poll: Hvis en CPU-avhengig prosess bruker 18 sekunder på en CPU, hvor lang tid bruker da 5 prosesser på 4 CPU-er?
os7del11.mp4
(04:57) Poll: Utregning av svar og kjøring av eksperiment
os7del12.mp4
(06:16) Slides: Multitasking og Multiprocessing, Multiprosessor og Multicore, Intel Core og AMD K10
os7del13.mp4
(04:08) Demo: amdock, serveren med 96 CPU-er som drifter VM-containerene
os7del14.mp4
(03:34) Slides: Hyperthreading
os7del15.mp4
(10:51) Demo: Hyperthreading på Linux-desktop rex med 8 CPU-er (eller 4?)
os7del16.mp4
(08:02) Demo: Hyperthreading og taskset
harek-haugeruds-macbook:~ hh$ uname -a Darwin dhcp-202-136.wlan.hio.no 9.5.1 Darwin Kernel Version 9.5.1: Fri Sep 19 16:19:24 PDT 2008; root:xnu-1228.8.30~1/RELEASE_I386 i386 |
Som vi ser er dette kjerneversjon 9.5.1 av Darwin og denne har en rettferdig måte å dele to CPU'er mellom tre prosesser på. Når man kjører det samme regn-scriptet, får man følgende resultat:
$ top -o cpu Processes: 48 total, 5 running, 43 sleeping... 176 threads 21:43:01 Load Avg: 3.16, 1.85, 0.83 CPU usage: 89.27% user, 10.73% sys, 0.00% idle PID COMMAND %CPU TIME #TH #PRTS #MREGS RPRVT RSHRD RSIZE VSIZE 170 bash 63.9% 2:33.80 1 13 19 192K 704K 692K 18M 168 bash 63.8% 2:56.34 1 13 19 192K 704K 692K 18M 169 bash 62.1% 2:35.43 1 13 19 192K 704K 692K 18M |
Man ser at tiden deles praktisk talt likt mellom de tre prosessene. Dette gjøres ved at tre prosessene med jevne mellomrom bytter på hvilken CPU de kjører på. Til en hver tid vil det kjøre to prosesser på samme CPU, men OS-scheduler bytter likt mellom dem, slik at de skifter på hvilken av prosessene som kjører alene på den andre CPUen.
haugerud@studssh:~$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 2 NUMA node(s): 1 Vendor ID: AuthenticAMD CPU family: 15 Model: 6 Model name: Common KVM processor Stepping: 1 CPU MHz: 2294.248 BogoMIPS: 4588.49 Hypervisor vendor: KVM Virtualization type: full L1d cache: 64K L1i cache: 64K L2 cache: 512K L3 cache: 16384K NUMA node0 CPU(s): 0-3 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx lm rep_good nopl extd_apicid pni cx16 x2apic hypervisor cmp_legacy 3dnowprefetch vmmcall |
Det vil si den har to sockets (to forskjellige brikker) med to Cores (CPUer) på hver. Men som man kan se av linjen hvor det står KVM, så er den egentlig en virtuell maskin (KVM står for Kernel-based Virtual Machine og er en type Linux virtualisering) og har derfor fått tildelt disse CPUene. Tidligere i semesteret var studssh konfigurert med bare to vCPUer (virtualCPU), dette kan konfigureres.
Ved å kjøre en CPU-intensiv prosess, får man følgende resultat:
haugerud@studssh:~$ time ./regn Real:9.962 User:9.940 System:0.004 99.82% |
Den bruker ca 10 sekunder. Hvis man kjører fem slike prosesser samtidig,
top - 13:04:52 up 27 days, 1:31, 19 users, load average: 1,11, 0,86, 0,61 Tasks: 268 total, 6 running, 261 sleeping, 1 stopped, 0 zombie %Cpu0 : 98,3 us, 0,3 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 1,3 st %Cpu1 : 97,7 us, 0,3 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,3 si, 1,7 st %Cpu2 : 95,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 5,0 st %Cpu3 : 98,7 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,3 si, 1,0 st KiB Mem : 8174752 total, 4926648 free, 363368 used, 2884736 buff/cache KiB Swap: 950268 total, 846168 free, 104100 used. 7368460 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND P 7495 haugerud 20 0 14648 3284 3092 R 85,1 0,0 0:04.47 regn 1 7493 haugerud 20 0 14648 3184 2980 R 81,8 0,0 0:04.38 regn 0 7497 haugerud 20 0 14648 1040 940 R 80,9 0,0 0:04.32 regn 3 7498 haugerud 20 0 14648 3228 3036 R 79,5 0,0 0:03.86 regn 0 7491 haugerud 20 0 14648 3280 3084 R 71,0 0,0 0:03.93 regn 2 |
vil de fem prosessen kjøre samtidig på de fire CPUene, slik at det til en hver tid er to prosesser på en av CPUene. I top-utskriften over, kan man se av P-kolonnen helt til høyre at det er CPU nr 0 som har to prosesser. OS skifter fortløpende på hvilken CPU som har to prosesser, slik at alle de fem prosessene får omtrent like mye CPU-tid hver, ca 80%.
Når en prosess tar 10 sekunder, vil det kreves 5x10 = 50 CPU-sekunder for å fullføre alle de fem jobbene. Arbeidsmengden blir fordelt likt på fire CPUer og det vil da ta 50/4 = 12.5 sekunder å fullføre hver jobb. Og dette resultatet får man om man kjører fem jobber samtidig.
haugerud@studssh:~$ for i in {1..5}; do time ./regn& done
Real:12.208 User:10.060 System:0.016 82.54%
Real:12.241 User:10.060 System:0.020 82.34%
Real:12.366 User:9.964 System:0.024 80.76%
Real:12.869 User:10.200 System:0.008 79.32%
Real:13.143 User:10.076 System:0.032 76.90%
|
Som forventet bruker jobbene ca 12.5 sekunder på å bli ferdig. Man kan også beregne at om man bruker 80% CPU i 12.5 sekunder vil man tilsammen bruke 10 CPU-sekunder. Det kan man også se av output, User: viser hvor mange CPU-sekunder hver prosess har brukt.
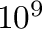 ) instruksjoner i sekundet.
Hvis CPU-en måtte vente på data fra RAM for hver instruksjon den skulle gjøre,
ville mange prosesser gått ti ganger så sakte som de gjør nå. For å kunne mate en hurtig prosessor med
instruksjoner og data raskt nok, bruker man flere nivåer av mellomlagring av data, såkalt cache-minne. Ordet cache kommer fra fransk
og betyr et hemmelig lager. Det går vesentlig
raskere å hente minne fra cache-minnet enn fra internminnet. I tillegg har det vist seg at de fleste programmer i 90% av
tiden utfører instruksjoner innenfor 10% av det totale minnet. Når CPU ber om en instruksjon som ligger et bestemt sted i
minnet, hentes derfor ikke bare denne instruksjonen, men for eksempel 32 KByte av minnet. Alt dette lagres i cache og når
CPU ber om neste instruksjon, ligger den ofte i cache, slik at den ikke må hentes fra internminnet. Fig. 45 viser
noen typiske størrelser og aksesstider for de sentrale lagringsmedien som finnes i en datamaskin, fra registre til harddisk.
Legg spesielt merke til den store forskjellen i aksesstid mellom internminnet og harddisk.
) instruksjoner i sekundet.
Hvis CPU-en måtte vente på data fra RAM for hver instruksjon den skulle gjøre,
ville mange prosesser gått ti ganger så sakte som de gjør nå. For å kunne mate en hurtig prosessor med
instruksjoner og data raskt nok, bruker man flere nivåer av mellomlagring av data, såkalt cache-minne. Ordet cache kommer fra fransk
og betyr et hemmelig lager. Det går vesentlig
raskere å hente minne fra cache-minnet enn fra internminnet. I tillegg har det vist seg at de fleste programmer i 90% av
tiden utfører instruksjoner innenfor 10% av det totale minnet. Når CPU ber om en instruksjon som ligger et bestemt sted i
minnet, hentes derfor ikke bare denne instruksjonen, men for eksempel 32 KByte av minnet. Alt dette lagres i cache og når
CPU ber om neste instruksjon, ligger den ofte i cache, slik at den ikke må hentes fra internminnet. Fig. 45 viser
noen typiske størrelser og aksesstider for de sentrale lagringsmedien som finnes i en datamaskin, fra registre til harddisk.
Legg spesielt merke til den store forskjellen i aksesstid mellom internminnet og harddisk.
Både CPU-registre og cache er laget av SRAM (Static RAM). Aksess er meget hurtig og SRAM er statisk i den betydning at det ikke trenger å oppfriskes, slik DRAM (Dynamic RAM) må. Mer en 10 ganger i sekundet må DRAM opplades, ellers forsvinner informasjonen. SRAM består av 6 transistorer for hver bit som lagres, til sammenligning består en NOT-port av to transistorer og AND og OR-porter av 4. Men DRAM trenger bare en transistor og en kapasitator(lagrer elektrisk ladning) for å lagre en bit. Derfor er DRAM billigere, mindre og bruker mindre effekt og kan derfor lages i større enheter. Internminnet består derfor av DRAM eller forbedrede varianter av DRAM. DDR4 SDRAM (Double-Data Rate generation 4 Synchronus Dynamic RAM) ble lansert i 2014 og i 2020 kom DDR5 som er det foreløpig siste av leddene i kjedene av forbedrede utgaver av DRAM.
![\includegraphics[width=12cm]{fig/osaCache1.eps}](img65.png)
|
Cache inneholder både data og instruksjoner og deler av MMUs (Memory Management Unit) page-tables i TLB (Translation Lookaside Buffer). I L1 cache er ofte disse separert i egne enheter, mens L2 cache pleier å være en enhet. I de senere årene har man klart å få plass til L2 på selve prosessorchip'en (den lille brikken som utgjør mikroprosessoren, bare noen kvadratcentimeter stor).
Arkitekturen til en moderne prosessor kan da i grove trekk se ut som i Fig. 78.
![\includegraphics[width=12cm]{fig/osaCache2.eps}](img66.png)
|
Noen arkitekturer har i tillegg enda et lag i minnehierarkiet, en offchip L3 cache som sitter mellom mikroprosessoren og RAM.
![\includegraphics[width=12cm]{fig/dualcore.eps}](img67.png)
|

|
En forskjell er at Intel Core i7 har hyperthreading i motsetning til de foregående Intel Core 2 prosessorene. Dermed kan den kjøre åtte prosesser samtidig. Men som vi skal se senere, for svært CPU-krevende prosesser har ikke dette så stor betydning, de må dele på beregnings-enheten, ALU.
Merk forøvrig: 30 MHz var maks klokkefrekvens for Intel i 1992 og den ble mer enn tredvedoblet på åtte år fram til 2000 hvor de første GHz prosessorene kom. Men på de neste åtte årene ble frekvensen bare tredoblet. Det at det er vanskelig å øke klokkefrekvensen har gjort at man istedet har økt kapasiteten med multi core og hyperthreading.
Serveren amdock som er fysisk server for alle Linux-VMene (som egentlig er docker containere) har en AMD CPU modell som heter EPYC 7552 og det er en 64-bit 48-core x86 server-mikroprosesser designet av AMD i 2019. Hver core(kjerne) har SMT (Simultanious Multithreading) slik at OS ser 96 CPU-er. Den er basert på AMDs Zen 2 mikroarkitektur. Den har 3MB L1-cache, 24 MB L2 cache og 192 MB L3 cache. Videre har den 768 GB RAM.
Hyperthreading er Intels eget markedsføringsbegrep for denne teknologien. Den generelle betegnelse er SMT (Simultaneous multithreading) og AMD har implementert SMT i noen av sine mikroartkitekturer som i Zen.
Desktop'en rex har en Intel i7 prosessor som har 4 kjerner(cores) som er hyperthreading og lscpu gir følgende:
rex:~$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 58 Model name: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz Stepping: 9 CPU MHz: 1711.156 CPU max MHz: 3900,0000 CPU min MHz: 1600,0000 BogoMIPS: 6785.02 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K |
Dette er ikke en VM men en fysisk node som har en socket med 4 cores og 2 threads per core. Det gir tilsammen 8 CPUer, output fra lscpu omtaler hver regneenhet som en CPU. Men 2 threads per core betyr i denne sammenhengen at hver core er hyperthreading som forklart over og egentlig er en regneenhet med en enkelt ALU men dobbelt sett av registre slik at en core kan kjøre to prosesser samtidig. Hvordan dette ser ut i praksis skal vi her teste.
Som før bruker vi følgende CPU-slukende program:
#! /bin/bash
(( max = 300000 ))
(( i = 0 ))
(( sum = 0 ))
while (($i < $max))
do
(( i += 1 ))
(( sum += i ))
done
echo $0, resultat: $sum
|
Slik ser det ut på rex om man starter 10 CPU-intensive regnejobber:
rex:~/regn$ for i in {1..10}; do time ./regn & done
|
top - 21:19:30 up 26 days, 9:10, 2 users, load average: 3,72, 2,59, 2,12 Tasks: 395 total, 11 running, 384 sleeping, 0 stopped, 0 zombie %Cpu0 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu1 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu2 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu3 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu4 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu5 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu6 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu7 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st KiB Mem : 16385632 total, 5192648 free, 5303528 used, 5889456 buff/cache KiB Swap: 16730108 total, 16698824 free, 31284 used. 10271192 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND P 32596 haugerud 20 0 14068 908 804 R 90,0 0,0 0:17.55 regn 0 32599 haugerud 20 0 14068 3020 2808 R 83,7 0,0 0:16.54 regn 4 32598 haugerud 20 0 14068 912 808 R 83,4 0,0 0:17.08 regn 6 32584 haugerud 20 0 14068 940 836 R 82,7 0,0 0:16.71 regn 1 32595 haugerud 20 0 14068 2872 2660 R 79,7 0,0 0:15.93 regn 3 32587 haugerud 20 0 14068 2932 2720 R 79,4 0,0 0:17.39 regn 1 32597 haugerud 20 0 14068 2944 2728 R 78,1 0,0 0:18.73 regn 5 32600 haugerud 20 0 14068 900 800 R 78,1 0,0 0:15.61 regn 3 32588 haugerud 20 0 14068 2956 2740 R 75,7 0,0 0:16.41 regn 2 32592 haugerud 20 0 14068 904 800 R 68,8 0,0 0:15.54 regn 7 |
Linux-kjernen betrakter dette som åtte uavhengige CPU'er og kjører prosesser på alle åtte. Av kolonnen P kan vi se at OS fordeler prosesser på alle CPUene og dermed må det være to prosesser på to av dem, i dette tilfellet på prosessor nummer 1 og 3. OS bytter med jevne mellomrom på hvilke CPUer som har to prosesser, slik at som man kan se av time-kolonnen, alle prosessene får omtrent like mye CPU-tid og avslutter samtidig. CPU-kolonnen viser andel CPU de siste 3 sekundene og her kan vi se at det er litt forskjell. Men i snitt får de omtrent 4/5 dels eller 80% CPU-tid. Det koster litt overhead å flytte en prosess fra en CPU til en annen, så det skjer ikke altfor ofte. (Når man kjører top må man taste 1 for å se de 8 øverste CPU-linjene og f fulgt av p og return for å se hvilke prosessorer som brukes).
top at de jobber på hver sin CPU og at de hver får 100% CPU-tid. Men hvordan kan man finne ut om de virkelig gjør det?
På samme måte som om man ønsker å finne ut om åtte arbeidere man har ansatt for å skrelle poteter virkelig jobber samtidig. Man tar tiden på dem. Åtte personer bør bruke like lang tid på å skrelle åtte sekker poteter som fire stykker bruker på fire sekker poteter. Ihvertfall hvis de har en potetskreller (ALU) hver. Men hvis to og to av arbeiderne må dele på samme potetskreller, tar det dobbelt så lang tid.
Så vi setter igang fire regnejobber som skreller ivei på hver sin av de fire CPU-ene:
rex:~/regn$ for i in {1..4}; do time ./regn & done
Real:18.152 User:18.144 System:0.000 99.96%
Real:18.401 User:18.392 System:0.004 99.97%
Real:18.417 User:18.412 System:0.000 99.97%
Real:18.516 User:18.508 System:0.000 99.96%
|
Jobben går unna på litt i overkant av 18 sekunder og det bør ikke ta lenger tid for åtte prosesser hvis de reelt sett jobber samtidig:
rex:~/regn$ for i in {1..8}; do time ./regn & done
Real:35.048 User:35.008 System:0.000 99.88%
Real:35.222 User:35.144 System:0.000 99.78%
Real:35.246 User:35.104 System:0.000 99.59%
Real:35.270 User:34.976 System:0.020 99.22%
Real:35.500 User:34.888 System:0.008 98.29%
Real:35.562 User:34.840 System:0.012 98.00%
Real:35.606 User:35.448 System:0.000 99.55%
Real:35.796 User:35.140 System:0.012 98.20%
|
Men det tar nesten dobbelt så lang tid. Som beskrevet tidligere, CPU-en har lastet inn to prosesser samtidig, men internt må de bytte på å bruke ALU-en og for slike prosesser som hele tiden bruker CPU har hyperthreading liten effekt. Det blir som om arbeiderne må bytte på å bruke samme potetskreller og da tar det dobbelt så lang tid å bli ferdig. Litt effekt har dog hyperthreading, det går litt mindre enn dobbelt så lang tid, som ville vært nærmere 37 sekunder.
rex:~/regn$ cat ram.c
#include <stdio.h>
int array[102400];
void main(){
int i,k;
for(k=0;k<2000000;k++){
for(i = 0;i < 1024;i++){
array[i] = i;
}
}
}
|
Hvis man kompilerer og kjører det, bruker det ca 4 sekunder på å kjøre ferdig.
rex:~/regn$ gcc ram.c rex:~/regn$ time ./a.out Real:4.021 User:4.016 System:0.004 99.97% |
Hvis man starter fire slike prosesser, sørger operativsystemet sin scheduler for at de kjører på hver sin ALU og alle bruker omtrent fire sekunder.
rex:~/regn$ for i in {1..4}; do time ./a.out& done
rex:~/regn$
Real:4.060 User:4.056 System:0.000 99.89%
Real:4.103 User:4.100 System:0.000 99.91%
Real:4.137 User:4.132 System:0.000 99.87%
Real:4.141 User:4.136 System:0.000 99.88%
|
Hvis man kjører åtte slike RAM-brukende prosesser samtidig, vil to og to av dem kjøre på samme core og dermed bytte på å bruke den samme ALU-en. Men i dette tilfellet vil det hele tiden være litt venting på RAM, slik at et lynhurtig bytte av hvem som bruker ALU kan gi en positiv effekt. Og det er hardware som utfører dette byttet, det blir i motsetning til for en vanlig prosess context switch ikke utført av operativsystemet.
rex:~/regn$ for i in {1..8}; do time ./a.out& done
rex:~/regn$
Real:4.345 User:4.336 System:0.000 99.80%
Real:4.370 User:4.332 System:0.000 99.12%
Real:4.371 User:4.364 System:0.000 99.85%
Real:4.371 User:4.368 System:0.000 99.94%
Real:4.425 User:4.420 System:0.000 99.89%
Real:4.437 User:4.424 System:0.000 99.70%
Real:4.479 User:4.328 System:0.000 96.62%
Real:4.496 User:4.328 System:0.000 96.27%
|
Og nå ser vi at hyperthreading har en meget stor effekt, til tross for at de må dele ALU bruker prosessen bare omtrent 10 % mer CPU-tid på å fullføre sammenlignet med når en prosess kjører helt alene på en core.
rex:~$ lscpu | grep name Model name: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz rex:~$ lscpu | grep Thread Thread(s) per core: 2 rex:~$ grep "" /sys/devices/system/cpu/cpu*/topology/thread_siblings_list /sys/devices/system/cpu/cpu0/topology/thread_siblings_list:0,4 /sys/devices/system/cpu/cpu1/topology/thread_siblings_list:1,5 /sys/devices/system/cpu/cpu2/topology/thread_siblings_list:2,6 /sys/devices/system/cpu/cpu3/topology/thread_siblings_list:3,7 /sys/devices/system/cpu/cpu4/topology/thread_siblings_list:0,4 /sys/devices/system/cpu/cpu5/topology/thread_siblings_list:1,5 /sys/devices/system/cpu/cpu6/topology/thread_siblings_list:2,6 /sys/devices/system/cpu/cpu7/topology/thread_siblings_list:3,7 |
Dette viser at CPUen har hyperthreading, siden den angir "2 threads per core". Når to prosess-enheter
deler samme ALU, kalles de "thread siblings" og listen over viser hvilke som hører sammen og deler ALU.
Den samme informasjonen kan man få grafisk med lstopo:
lstopo --no-io --no-caches |
gir følgende figur
For å skru av hyperthreading, kan man fjerne en PU (Processing Unit) fra hver av de fire siblings-parene i listen.
Alternativt en av PU'ene fra hver core i lstopo-figuren. Dette kan gjøres ved som root å overskrive en
setting i /sys/devices/system/cpu:
# for i in 4 5 6 7; do echo 0 > /sys/devices/system/cpu/cpu$i/online ; done |
Etter man har gjort dette, vil rex kun ha fire cores uten hyperthreadin og OS vil kun se disse fire og schedulere prosesser på disse fire.
Om man nå starter 8 regn-jobber på rex, ser det slik ut:
top - 12:10:49 up 27 days, 2 min, 1 user, load average: 4,66, 1,71, 0,95 Tasks: 345 total, 9 running, 336 sleeping, 0 stopped, 0 zombie %Cpu0 : 99,7 us, 0,3 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu1 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu2 :100,0 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st %Cpu3 : 99,3 us, 0,0 sy, 0,0 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,7 si, 0,0 st KiB Mem : 16385632 total, 4838284 free, 5646572 used, 5900776 buff/cache KiB Swap: 16730108 total, 16725972 free, 4136 used. 9934028 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29234 haugerud 20 0 14068 884 780 R 50,2 0,0 0:07.19 regn 29232 haugerud 20 0 14068 940 836 R 49,8 0,0 0:07.10 regn 29237 haugerud 20 0 14068 2956 2740 R 49,8 0,0 0:07.16 regn 29239 haugerud 20 0 14068 940 836 R 49,8 0,0 0:07.33 regn 29241 haugerud 20 0 14068 1056 956 R 49,8 0,0 0:07.10 regn 29243 haugerud 20 0 14068 884 780 R 49,8 0,0 0:07.10 regn 29242 haugerud 20 0 14068 888 784 R 49,5 0,0 0:07.26 regn 29244 haugerud 20 0 14068 912 808 R 49,2 0,0 0:07.07 regn |
De åtte jobbene deler på fire CPUer, to kjører på hver og får 50% CPU-tid. Totaltiden blir naturlig nok ganske nøyaktig det dobbelte av når bare fire prosesser kjører:
Real:36.553 User:18.260 System:0.004 49.96% Real:36.679 User:18.340 System:0.012 50.03% Real:36.839 User:18.356 System:0.000 49.82% Real:36.842 User:18.232 System:0.000 49.48% Real:36.854 User:18.216 System:0.008 49.45% Real:36.915 User:18.232 System:0.000 49.39% Real:37.098 User:18.368 System:0.000 49.51% Real:37.112 User:18.272 System:0.000 49.23% |
Litt overhead blir det av context-switching når to prosesser deler samme CPU, men ikke mye. Og vi ser at totaltiden blir litt over ett sekund lenger enn når hyperthreading var på, så en liten effekt har hyperthreading, selvom de to prosessene må dele ALU. For andre jobber kan hyperhtreading ha større effekt, spesielt hvis programmene ofte bruker RAM.
rex:~/regn$ for i in {1..4}; do time ./a.out& done
rex:~/regn$
Real:4.063 User:4.036 System:0.000 99.34%
Real:4.080 User:4.056 System:0.004 99.50%
Real:4.171 User:4.036 System:0.000 96.76%
Real:4.177 User:4.088 System:0.000 97.86%
|
Men når vi nå kjører 8 samtidige prosesser må operativsysteme schedulere to prosesser på hver CPU (core/kjerne/regnenhet/ALU) og la de to prosessene bytte på å bruke den ved konvensjonell multitasking styrt av OS. Da vil det totalt sett naturlig nok ta dobbelt så lang tid å fullføre alle prosessene:
rex:~/regn$ for i in {1..8}; do time ./a.out& done
rex:~/regn$
Real:8.034 User:3.988 System:0.000 49.64%
Real:8.077 User:3.980 System:0.000 49.27%
Real:8.083 User:4.040 System:0.000 49.98%
Real:8.139 User:4.036 System:0.008 49.68%
Real:8.137 User:3.988 System:0.000 49.00%
Real:8.139 User:3.988 System:0.000 48.99%
Real:8.163 User:3.996 System:0.004 49.00%
Real:8.176 User:4.124 System:0.000 50.43%
|
Dette er resultatet av OS-styrt multitasking og er helt forskjellig fra hva vi fikk når hyperthreading var skrudd på, da fikk vi følgende når nøyaktig samme program kjøres på samme maskin:
rex:~/regn$ for i in {1..8}; do time ./a.out& done
rex:~/regn$
Real:4.345 User:4.336 System:0.000 99.80%
Real:4.370 User:4.332 System:0.000 99.12%
Real:4.371 User:4.364 System:0.000 99.85%
Real:4.371 User:4.368 System:0.000 99.94%
Real:4.425 User:4.420 System:0.000 99.89%
Real:4.437 User:4.424 System:0.000 99.70%
Real:4.479 User:4.328 System:0.000 96.62%
Real:4.496 User:4.328 System:0.000 96.27%
|
Det går nå nesten dobbelt så fort og viser at hardware hyperthreading er mye mer effektivt en OS multithreading med context switch. En hyperthreading switch bruker bare noen nanosekunder og kan utnytte at en thread venter på RAM. En OS-context switch tar minst tusen ganger så lang tid og kan derfor ikke brukes til å effektivisere bort svært korte pauser i prosesseringen på grunn av venting på RAM.
taskset kan man eksplisitt forlange at en prosess kjører på en bestemt CPU. Det vil da medføre at man overstyrer OS sin scheduling av prosesser; OS vil alltid prøve å fordele arbeidsmengden så jevnt som mulig. Taskset kan være nyttig i mange situasjoner og kan også brukes til å belyse forskjellen på multithreading og hyperthreading. OS nummererer CPU-ene fra 0 til 7 om man har åtte av dem. Man kan låse en regnejobb til CPU nummer 0 og kjøre og ta tiden på den med
rex:~/regn$ time taskset -c 0 ./regn Real:18.042 User:18.036 System:0.000 99.96% |
(på forelesning ble rekkefølgen på time og taskset byttet og da blir tidsanvisningen anderledes) Hvis man tvinger to slike regnejobber til å kjøre på samme CPU vil de bruke dobbelt så lang tid:
rex:~/regn$ for i in 1 2; do time taskset -c 0 ./regn& done rex:~/regn$ Real:36.088 User:18.036 System:0.000 49.97% Real:36.206 User:18.164 System:0.000 50.16% |
Av prosenttallet ser vi at de får 50% CPU hver, likt fordelt fra OS som schedulerer under restriksjonen att begge alltid må kjøre på OS nr 0. Hvis man overlot scheduling til OS, ville de blitt plassert på hver sin core og fullført dobbelt så fort:
rex:~/regn$ for i in 1 2; do time ./regn& done rex:~/regn$ Real:18.431 User:18.428 System:0.000 99.98% Real:18.453 User:18.448 System:0.000 99.97% |
Fra før vet vi at CPU 0 og CPU 4 er siblings, det vil si sitter på samme core. Hvis vi med hyperthreading aktivert bruker taskset til å låse prosessene til disse to, vil det gå nesten like sakte som om de ble satt på samme CPU:
rex:~/regn$ for cpu in 0 4; do time taskset -c $cpu ./regn& done rex:~/regn$ Real:35.075 User:35.072 System:0.000 99.99% Real:35.080 User:35.072 System:0.004 99.99% |
Det kommandoen over tekninsk sett gjør er å gi variabelen cpu verdien 0 og 4 og løkken setter igang to prosesser, en på CPU 0 og en på CPU 4, som er siblings og sitter på samme core med en felles ALU.
Men hvis vi låser prosessene på nesten samme måte, men til CPU 1 og 4, vil det igjen gå nesten dobbelt så fort fordi vi nå eksplisitt har plassert dem på hver sin core, slik også OS gjør når to prosesser scheduleres:
rex:~/regn$ for cpu in 1 4; do time taskset -c $cpu ./regn& done rex:~/regn$ Real:18.470 User:18.468 System:0.000 99.98% Real:18.762 User:18.756 System:0.000 99.97% |
![\includegraphics[width=12cm]{fig/osaCache.eps}](img64.png)
![\includegraphics[width=6cm]{fig/rex.pdf}](img68.png)
![\includegraphics[width=6cm]{fig/rexnohyp.pdf}](img69.png)